基于改进Vision Transformer的蝴蝶品种分类
作者: 许翔 蒲智 鲁文蕊 王亚波
关键词:蝴蝶分类;Vision Transformer;卷积;Class token;VanillaNet;注意力机制
0 引言
蝴蝶作为昆虫纲中的一类分布广泛的生物,因其高度敏感的生态感知能力而备受研究关注。蝴蝶的行为反应具有一定的指示性作用,反映了生态系统的动态变化。各种人类活动、气候变化和食物来源等外部干扰因素都会威胁到它们的生存环境。不同品种的蝴蝶对环境的依赖性差异显著,因此,通过对蝴蝶的分类研究,可以更细致地根据蝴蝶各品种的行为习性判断当地生态环境的状况,并进行进一步研究。
蝴蝶属于昆虫纲、类脉总目、鳞翅目(Lepidop⁃ tera) 、锤角亚目(Rhopalocera) ,全球已知近2万种,可以分为4总科、17科、47亚科、1 690属和15 141种。中国本土的蝴蝶资源也十分丰富,包括12科、33亚科、434属和2 153[1-2]。蝴蝶的触角主要呈现棒状或锤状,细长,触角底部略有加粗,主要在白天活动。蝶翅宽大,其翅膀上具有翅抱连锁器,停歇时翅竖立于背上,身体相对纤细[3]。
蝴蝶识别任务艰巨,因为蝴蝶自身的区分度并不明显。传统的识别方法是通过形态学特征来辨别,这需要研究者具备丰富的识别经验以及对蝴蝶外形特点的理论基础,才能精准确定蝴蝶的大致类别。这使得研究进展缓慢。此外,研究者在外采集蝴蝶信息时多是用数码产品进行拍摄,拍摄距离和背景均会影响人们对照片中蝴蝶品类的判断。因此,研究者可以借助工具快速高效地进行蝴蝶分类,在此基础上结合理论基础与识别经验,最终确定蝴蝶的具体种类。
准确高效的蝴蝶分类吸引了大量蝴蝶爱好者和研究工作者的注意。通过计算机图像分类技术,可以通过一张图片上的蝴蝶形态学特征快速确定具体种类。图像处理技术提取各类图像的特征,使计算机能够像人类一样理解和解释图像内容。蝴蝶分类方法也经过了多轮技术迭代,最初是野外观测并采集数据以及标本制作,随后是传统数字图像分类方法,需要人工采用特征或统计信息(均值、方差等)、直方图、频率域特征等基本特征。最后是使用神经网络直接对整张输入图片进行特征提取和自动识别。
潘鹏亮等[4-5]和陈渊等[6]通过提取蝴蝶前翅的内部翅脉交点坐标,对这些翅脉特征进行聚类来识别蝴蝶。2011年,Wang等[7]人采用蝴蝶标本数据集,通过基于内容的图像检索(CBIR) 技术,使用不同特征、特征权重和相似度匹配算法进行对比实验,得出形状特征对分类比其他形态学特征更为重要,其中凤蝶科的分类准确率达到84%。李凡[8]在2015年利用OpenCV 对50种蝴蝶标本750张数据进行预处理,再进行多尺度轮廓曲率特征提取,最后使用改进的K近邻方法对标本进行分类,取得整体96.8%的准确率。这些方法主要通过手工对标本进行形态学特征提取,无法获取深层语义信息,且对蝴蝶标本图片的识别效果不佳,泛化能力较差,并需要进行复杂的提取工序,费时费力。
2018年,谢娟英等[9]改进Faster-RCNN的结构,对94 类自然蝴蝶照片进行目标检测任务,取得了比YOLO v2/v3 更好的效果。2019 年,李策等[10]将ResNet101 的卷积结构改成可变形卷积,以更好地自适应确定蝴蝶的形变尺度和位置。同时,他们采用了迁移学习来加速模型的收敛,取得了显著效果。2021年,谢娟英等[11]在改进Retina-Net 时引入了可变形卷积和注意力机制,进一步提高了模型的泛化能力。
近年来,深度学习技术在图像分类任务中取得了突破性进展,特别是卷积神经网络(CNN) 的出现,极大地提高了图像分类性能。CNN通过多层卷积层和池化层自动学习图像的局部特征和全局结构,有效减少了对手工特征设计的需求。深度学习模型具有强大的表达能力和泛化能力,能够处理大规模数据集和复杂任务。2020年,谷歌大脑团队基于Transformer 在自然语言处理(NLP) 领域的成功,将Transformer引入视觉领域,采用卷积对图像进行分块,再输入Transformer En⁃ coder,在ImageNet-1k数据集上的Top-1分类准确率达到77.91%。
本研究提出了一种基于Vision Transformer(VIT) 并进行了改进的图像分类模型。对VIT网络结构的Patch Embedding和Class token进行了修改,旨在提高VIT在小数据集上的鲁棒性,并显著提升模型的预测结果。研究建立了一个能够自动对蝴蝶品种进行分类的模型,为解决VIT在小数据集上从头训练效果不佳的问题提供了有效的改进思路。
1 基于VIT 改进的VC_VIT 网络模型
1.1VIT 网络模型分析
Transformer最初在自然语言处理(NLP) 领域取得了显著的成功。2020年,Alexey Dosovitskiy[12]等人将fTorramnesrfo(VrmiTe)r 在引图入像计分算类机任视务觉中领展域现,其了中令V人is瞩ion目 T的ran效s⁃果。这得益于Transformer强大的注意力机制,其性能优势在大量数据的情况下持续提升。ViT在使用极其庞大的训练数据集时,可以远远超越卷积神经网络(CNN) 的性能水平。
然而,ViT需要使用大量数据,这导致模型训练时需要更多的计算资源和时间。另外,ViT在小数据集上的表现并不突出,这主要源于其缺少卷积所具有的归纳偏置。作为一种深度学习模型,ViT使用自注意力机制而非传统的卷积层进行特征提取,因此缺乏卷积操作,没有卷积层中的归纳偏置。CNN可以通过共享权重和局部连接更容易地从有限的数据中泛化。
此外,由于ViT本身的自注意力机制具有全局关系建模的能力,相对于卷积操作,其在捕捉局部特征方面存在一定的不足。这使得在小型数据集上训练时,ViT容易过拟合,性能相对较差。
1.2 网络结构改进
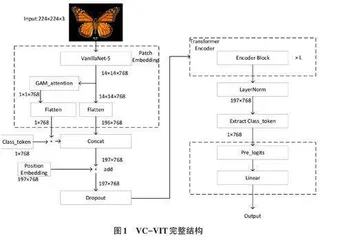
ViT 的结构主要包括一层卷积、多层编码器(Transformer Encoder) 和最后的全连接分类头。每个编 码 器 层 包 括 自 注 意 力 机 制 (Multi-Head Self- wAottrekn)t 。ion这) 和些前编馈码神器层经有网助络于(Fe模ed型-F捕or捉wa图rd像 N块eur之al 间Ne的t⁃特征关系。然而,鉴于ViT存在缺乏卷积具有的归纳偏置、对数据量要求高以及容易过拟合等缺点,本文对其进行了改进,改进的重点集中在Patch Embedding 和Class token两个部分。改进后的结构如图1所示。
1.3 Patch Embedding 改进
为了解决ViT在局部信息缺失方面的问题,经过一系列与现有经典网络和新兴卷积神经网络的对比,最终选择了VanillaNet-5(以下简称V5) [13]对图像进行切块。V5以其简单而高效的结构在准确率方面取得了显著的成绩。通过在VanillaNet的Stage 1至Stage 3 部分引入残差结构与SE压缩激励机制[14],提高了对图像特征的提取效果。引入压缩激励机制有助于对特征通道进行权重聚合,使模型更加关注关键的特征信息,并且其轻量化的设计也不会带来过多的计算开销,从而提高模型的分类准确率和鲁棒性。同时,SE 模块能够自动学习不同特征通道的权重,从而更好地适应不同的数据集和任务。
1.4 Class token 改进
Class token 是ViT 架构中最重要的组成部分之一,其输出在图像分类的最后阶段得到应用。通过在Class token上应用全连接层,模型能够学到如何将全局信息与局部信息有效结合,从而做出更为准确的分类决策。Class token对整个图像信息进行建模,并承载了图像的全局信息表示。Class token的引入有助于使ViT模型更好地捕捉整个图像的语义信息,而不仅仅是局部的图像块信息。如表1所展示的改进后V5模型结构,V5模型的stage 3(out_conv) 经过一系列处理后有两个重要输出:V5_out1对通过卷积提取到的图像内容特征进行了切块;V5_out2 通过全局注意力机制(Global Attention Mechanism,简称GAM) [15]感知到图像空间和通道上的双重信息,用于ViT Class token快速学习到图像的全局信息,结构如图2所示。
GAM注意力机制主要用于增强模型对全局信息关注,保留图片通道和空间方面的信息,以增强跨维度交互,同时有助于减少信息弥散,放大全局交互的效果。由于ViT的编码器只能接收转化成序列的图片,初始训练阶段Class token并不能快速捕捉到图像空间与通道上的信息,导致训练进程相对缓慢。将GAM对图像全局处理的结果与Class token相加,以加速Class token对整个图片的快速建模,使得模型更快收敛。
2 相关工作
2.1 数据集介绍
本文所使用的数据集来自Kaggle,包含100类蝴蝶的野外拍摄图像,共计24 277张图片,样本分布如图3所示。在数据划分方面,按照7∶2∶1的比例进行划分,其中训练集包含17 066张图片,验证集包含4 813张图片,测试集包含2 398张图片。数据样本的分布相对均匀,每个类别都包含100张以上的样本,如图4所示是部分蝴蝶的生态照片。
2.2 实验相关配置
实验平台为Windows 10,GPU为Tesla T4×2,显存为16G。本文采用Meta平台的PyTorch 2.0深度学习框架在PyCharm上搭建和训练模型,训练次数为70。分类损失函数使用交叉熵损失函数(CrossEntropy⁃ bLeols_ss) m,oo并thin配g参合数标设签为0平.1。滑优(l化ab器el 采sm用ooAthdinamg), 学,l习a⁃率为0.001,学习率更新策略使用余弦退火(CosineAn⁃ nealingLR) 。batch_size 设置为32,使用早停机制(Early Stopping) ,当验证集损失连续7次不下降时,则终止训练以节约资源进行新一轮实验。
2.3 数据集预处理
数据增强可以通过对训练数据进行变换和扩充来增加模型训练样本的数量,主要目的是提高模型的泛化能力,使其在面对新的、未见过的数据时表现更好。尽管每次训练时使用的是同一批图片,但是由于经过一系列的数据增强操作,变相地增加了样本的多样性,减缓了过拟合现象,并提高了模型对变化的鲁棒性。另外,通过现有数据生成大量变体,可以降低数据采集的成本,同时达到更好的分类效果。下面是实验阶段具体的数据增强操作:
1) 对图像进行统一缩放至256×256大小。
2) 将图像随机水平和垂直翻转,翻转概率为0.5。
3) 将图片随机旋转,旋转角度为[-45°, 45°],概率为0.5。
4) 将图片进行裁剪,裁剪为224×224大小。
5) 对图片进行cutout操作,将224大小的图片随机镂空8块2×2像素的区域,镂空处像素值变为0,是否镂空该张图片的概率为0.5。
6) 对图片进行归一化处理,然后放进网络中进行训练。
2.4 模型性能评价指标
模型性能评价指标用来度量机器学习或深度学习模型在特定任务上的性能。为了直观地观察不同模型在分类任务上的性能差异,本文采用以下评价指标:1) 准确率(Top1-Acc) :模型正确分类的样本所占的比例。2) Top-5 准确率(Top5-Acc) :每个样本的正确类别标签位于模型预测的前五个类别之一的比例。3) 平均精确率(MacroAvg-Precision) :所有类别上精确率的宏平均值。4) 平均召回率(MacroAvg-Recall) :所有类别上召回率的宏平均值。5) 平均F1分数(Mac⁃ roAvg_F1) :所有类别上F1分数的宏平均值。