协同过滤推荐算法在大数据旅游推荐系统中的应用
作者: 孙俊玲 王高平 胡永坤
关键词: 基于用户的协同过滤;基于项目的协同过滤;旅游推荐服务;爬虫;旅游推荐系统
0 引言
随着“互联网+”的快速发展,旅游行业的互联网化已经成为一种不可忽略的趋势。伴随着消费水平的上升,旅游市场亦在持续扩展,旅游数据也在不断增加,同时旅游产品的种类和数量也在快速增加。这给用户在选择旅游目的地、产品和服务时带来了巨大的挑战。对于旅游服务提供商而言,如何利用人工智能推荐算法结合大数据,为用户提供个性化、高效的旅游推荐服务,以吸引更多用户并提高用户留存率和转化率[1],是提升竞争力的关键。
1 基于大数据的旅游推荐系统
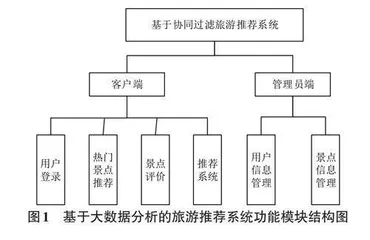
基于大数据的旅游推荐系统是一个复杂的系统,涵盖了多个方面。该系统需要收集、处理和分析大量的旅游景点和用户数据,以提供有效的信息和决策支持。其主要任务和功能包括:
1) 利用网络爬虫技术收集数据。从互联网上大规模爬取和筛选旅游景点信息,然后进行清洗和标准化处理。这一步骤确保了数据的质量和一致性,为后续分析和推荐的准确性奠定基础。
2) 用户个性化推荐。根据用户的兴趣及使用情况,采用推荐算法,为用户提供最适合其需求的旅游服务,从而提升服务的精确度和用户满意度。
3) 数据的可视化与分析。利用数据可视化技术,将丰富的信息转化为图表与图像,帮助用户更好地了解当前市场趋势、旅游景点的热度和价格。见图1。
通过这样的系统架构,旅游推荐服务能够更加智能化和高效地满足用户的需求,同时也为旅游服务提供商带来了更多的客户和业务增长。
2 数据爬取与清洗
2.1 数据爬取
使用WebMagic爬虫从互联网上爬取景点信息记录,通过爬虫工具从各旅游网站收集景点信息数据。这些数据包括景点名称、等级、地址、介绍、热度、价格、月销量、经纬度、景点图片、省份、城市、行政区等详细信息。通过预处理和清洗操作,对收集的数据进行整理,形成一个全面的旅游大数据库。
爬虫流程如下:1) 使用requests 库发送HTTP 请求。2) 获取数据,服务器响应后,保存整个页面信息。3) 解析HTML页面,查找并提取所需数据。4) 存储数据,将获取的数据保存到文件中。
2.2 数据清洗
数据清洗的主要工作包括:1) 数据清理。删除无关数据或错误数据,处理缺失值。2) 数据转换。将数据转换为适合计算和分析的格式或形式。3) 特征提取。将数据转化为适用的向量等。
为了确保结果的准确性和可靠性,所收集的数据必须经过数据清理和标准化处理,以确保数据的完整性和一致性。具体工作流程包括:1) 读取数据。2) 查找缺失值。3) 删除缺失值很多的数据。4) 填补缺失值。5) 检验和更正错误数据。6) 删除重复数据。7) 保存数据。
对旅游景点的指标数据进行筛选,过滤掉不符合数值规范的数据。主要流程如下:
1) 设置指标范围字典。2) 遍历每个旅游景点数据,对每个景点信息遍历每个指标。3) 判断数值是否符合规范,过滤不符合标准的数据。4) 将符合标准的数据加入过滤后的数据列表中。
清洗后的数据需要进行标准化,目的是将不同尺度的数据缩放到同一维度。使用MinMaxScaler函数进行数据缩放,将数据缩放到[0,1]的范围内,这样方便后续的加权计算和相似度计算。
3 推荐算法
3.1 基于用户的协同推荐[2]
重点利用用户的历史行为数据,通过寻找与用户兴趣相似的其他用户的行为来生成推荐。这种方法的核心思想是“人以群分”,即认为具有相似兴趣的用户会喜欢相似的物品。因此,它倾向于推荐那些与用户历史行为相似的其他用户喜欢的物品。这种推荐方法的好处是可以充分利用用户的历史行为数据,为用户提供个性化的推荐,而且对于新物品也有一定的推荐能力。然而,它也存在一些问题,比如可能会受到数据稀疏性和冷启动问题的影响,即对于新用户或者新物品,由于缺乏足够的历史行为数据,很难进行准确的推荐。
具体过程:1) 初始化相关参数,包括找到与目标用户兴趣相似用户数(self.n_sim_user) 和为其推荐的景点数(self.n_rec_movie) 。2) 读入数据集文件并将其划分为训练集和测试集。3) 计算用户之间的相似度矩阵。首先,将数据集中的每个景点与看过该景点的用户建立倒排索引表[3];然后,对于每一对用户,计算它们在共同观看景点的数量,进而计算这些用户之间的相似性;对于目标用户,可以根据上述方法找到最相似的K个用户,并根据这些用户对未观看过的景点进行推荐。最终,返回N个值得推荐的景点。
根据推荐结果对推荐效果进行评价,推荐系统的效果评价主要通过以下指标进行:1) 准确率(Preci⁃ sion) 。表示推荐的景点中有多少是用户实际感兴趣的景点。2) 召回率(Recall) 。表示用户实际感兴趣的景点中有多少被推荐出来。3) 覆盖率(Coverage) 。表示推荐算法能够覆盖多少不同的景点。
这些指标能够全面反映推荐系统的性能和用户满意度,帮助持续优化推荐模型,提升用户体验。
3.2 基于物品的协同过滤推荐
基于物品的协同过滤推荐主要侧重利用用户的历史行为数据,通过计算物品之间的相似度来发现用户的潜在兴趣。它倾向于推荐与用户之前喜欢过的相似物品,因此在推荐结果上可能具有较高的个性化和准确性。然而,这种推荐方法可能存在一定的局限性,例如它可能会导致信息闭环,即用户只会接触到与自己此前兴趣相似的物品,缺乏多样性。此外,对于新物品或者用户行为数据稀疏的情况下,基于物品的协同过滤推荐的效果可能会受到影响。
基于物品的推荐算法通过计算景点之间的相似度,为目标用户推荐一些可能感兴趣的景点。具体算法过程如下:
1) 初始化参数。包括要找到的相似景点数量和要推荐的景点数量等。2) get_dataset。从文件中读取数据集,将数据集划分为训练集和测试集。3) lcoaalcd__mfiloev。ie_读sim取。文计件算景并点返之回间文的件相的似度每。一5)行 re。com4⁃) mend。为目标用户推荐景点。6) evaluate。根据准确率、召回率和覆盖率对推荐进行评估。
其中,calc_movie_sim方法[4]是该算法的核心,它通过计算训练集中每一对景点之间的共同出现次数,使用余弦相似度得到景点之间的相似度。即,两者之间的相似度等于它们共同被用户评价的次数除以它们分别被评价次数的乘积。在相似度计算之前,该方法还计算了每个景点的受欢迎程度,以便在相似度计算中对景点的受欢迎程度进行加权。
recommend方法则是用于为目标用户推荐景点的方法。它根据目标用户已经看过的景点,找到与这些景点相似的K个景点,并从中选出评分最高的N个景点进行推荐。
evaluate方法用于评估该算法的准确率、召回率和覆盖率[5]。
3.3 相似度计算与评分公式
推荐算法的核心在于相似度的计算。根据计算特征及数学原理,相似度计算方法大致分为两类:一类是基于相似度指标,例如斯皮尔曼的相关性;另一类是基于距离指标,例如欧氏距离、曼哈顿距离等。斯皮尔曼的相关性见公式(1) 。
式中,x 和y 表示两个向量,xi 和yi是向量x 和y 的分量,n是向量的维数。
余弦相似度既不属于基于相似度指标的方法,也不完全属于基于距离指标的方法。它通过测量两个向量的夹角的余弦值来评估它们之间的相似程度。余弦相似度的取值范围为-1~1,数值越接近1表示两个向量越相似,数值越接近-1表示两个向量越不相似,数值接近0表示两个向量之间没有明显的相似性。余弦相似度特别适用于处理高维数据,因为它对向量的长度不敏感,只关注其方向。余弦相似度[6]的计算公式如下:
式中:x 和y 表示两个向量,x·y 表示向量x 和向量y 的点积,||x||和||y||表示向量x 和向量y 的模长。xi和yi为向量x 和y 的分量,n为向量的维数。
协同过滤的评分公式是基于用户的历史行为数据和其他用户的行为数据来预测用户对商品的评分。通过计算用户之间或商品之间的相似度或相关系数,可以找到与用户兴趣相似的其他用户或商品,并利用这些相似用户或商品的行为数据来预测目标用户对目标商品的评分。这种方法可以帮助用户发现他们可能感兴趣的新商品或内容。加权预测评分公式[7]见公式(3) 。
式中:n 为影响因素的数量, Wkb为b 项目在k 因素中的权重,rka是a 项目在第k个因素的值,rib是i 用户对b 项目的评分。
4 实验结果对比分析
首先,将上述两种算法:基于物品(ItemCF) 的推荐算法和基于用户(UserCF) 的推荐算法,在公开的Mov⁃ ielens 1M数据集上进行实验验证。ml-1m是推荐领域常用的测试数据集,很多有效的研究成果都是基于该数据集进行验证的。该数据集包含943 个用户、1 682个项目和100 000条评分。下载后的数据分别是users.dat、movies.dat、ratings.dat,另外还需要links和tags文件。
实验结果统计表如表1所示:
根据实验结果,可以看到ItemCF和UserCF的P、R值。P代表Precision,即正确结果占所有预测结果的比例。在此结果中,ItemCF 的P 值为0.261 4,UserCF的P值为0.281 8。这意味着在所有预测项目中,ItemCF 和UserCF 正确预测的项目占比分别为26.14%和28.18%。R代表Recall,表示预测正确的项目占所有真实项目的比例。在此结果中,ItemCF的R 值为0.0705,UserCF的R值为0.075 8。这意味着在所有真实项目中,ItemCF和UserCF正确预测的项目占比分别为7.05%和7.58%。
从Precision(P) 和Recall(R) 指标来看,UserCF 模型的性能略高于ItemCF模型。这意味着UserCF模型能够更准确地预测用户会喜欢的物品,并且能够更全面地推荐物品。然而,从Coverage指标来看,ItemCF 模型的性能略高于UserCF模型。这意味着ItemCF模型能够覆盖更多的物品,从而为用户提供更多的选择。
综合考虑这些指标,如果在进行景点推荐时更注重推荐的准确性和全面性,则UserCF模型可能更适合;如果注重推荐的覆盖率,那么ItemCF模型可能更适合。在推荐系统中,使用UserCF模型对景点进行推荐,可以找到与目标用户兴趣相似的4个用户,并为其推荐4个景点。通过读取文件获取“用户-景点”数据,通过训练集和测试集计算用户的相似度,并将结果保存在用户相似度矩阵中。在推荐系统中,同样使用ItemCF模型对旅游景点进行推荐;综合这两种推荐方法,使用ItemCF推荐模型可以提高推荐景点的覆盖率,而使用UserCF模型则可以提高推荐景点的准确性和全面性。综合这两种推荐方法可以得到使用户更满意的推荐结果。
5 结论
本文主要介绍了两种协同过滤推荐算法,以及算法的思想和代码实现。在公开数据集上对两种算法进行了测试,并使用训练集和测试集进行评估,通过准确率、召回率和覆盖率三个指标来评估推荐结果。实验结果表明,UserCF模型能够更准确地预测用户会喜欢的物品,并且能够更全面地推荐物品,获得了较高的准确率和召回率,但覆盖率略低。ItemCF模型能够覆盖更多的物品,从而为用户提供更多选择。