基于深度学习的网络流量入侵检测方法研究
作者: 李浩
摘要:在电子信息技术快速发展的过程中,网络入侵模式、攻击方式也在不断升级和变化,网络安全问题日益严峻,网络流量入侵检测面临更大挑战。为了提高入侵检测的速率、准确率,文章提出一种基于深度学习的网络流量入侵检测新方法,该方法通过提取流量数据的关键特征,优化粒子群算法。同时引入惯性权重模块,并结合极限学习机、AE自编码器,有效消除数据噪音的问题,实现对网络流量入侵的有效检测。实验结果表明,该方法能够精确、高效地对网络流量入侵进行检测,可以提高网络安全防护效果。
关键词:深度学习;网络流量;入侵检测;检测方法
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)23-0096-04
开放科学(资源服务)标识码(OSID)
伴随着网络信息技术的迅猛发展,网络流量入侵载体更加多样化,网络安全受到严重威胁,亟须加强网络安全风险管理,提高入侵攻击侧识别速率,保障资产防护效果。对此,众多学者围绕网络流量入侵检测方法开展了大量的研究,取得了一定的研究成果。宗学军和刘欢欢等[1]针对当下入侵检测系统存在的不足,将数据平面开发套件技术同Suricate IDS进行整合,利用高效规则匹配算法NEW-WM,构建高速网络流量下入侵检测系统,有效解决了以往入侵检测系统无法准确、实时检测高速工业网络流量的问题,大大提升了系统数据包捕获处理能力和入侵检测效率;陈雪倩和步兵[2]提出一种基于网络流量和数据包的入侵检测系统,基于CBTC系统构建IDS模型,整合AR算法的网络流量检测模块和数据包检测模块,实现了对网络流量、数据包的特征提取和检测,有效保障了CBTC系统的安全风险,避免了数据篡改、杜绝服务等问题的发生;边金良[3]提出基于数据挖掘的网络流量异常入侵检测法,借助数据挖掘的关联分析功能,明确异常流量特征联系,对异常流量特征开展联合计算熵值处理,具有良好的异常网络流量入侵检测功能。上述方法虽然对于网络流量拥有良好的数据采集和处理能力,提升了网络流量入侵检测效率,缩短了检测时间,使入侵检测系统消耗大大降低,但在检测精确度、实时性检测和告警方面仍存在一定的不足,对入侵行为类型的检测有一定的局限性,适用范围有限,无法实现大规模广泛应用,对未知或新型攻击的检测方面仍有待提升,还需进一步提升实际应用性能。为了解决上述问题,本研究提出基于深度学习的网络流量入侵检测方法,联合深度学习、极限学习机的优势,并通过实验验证该方法的入侵检测性能。
1 基于深度学习的网络流量入侵检测方法设计
1.1 关键词维度统计特征
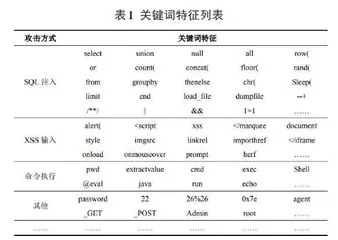
协议、流量包是网络流量入侵检测工作的关键识别信息。在对协议这一流量行为信息进行识别时,涉及TCP、IP、SLIP、PPP等几大网络协议,应通过One-Hot中单个类型单对应的形式,实现协议同相应数值的映射处理;而在流量数据包的识别方面,对于特定平台,提前要在该平台服务器中部署脚本监听端口,抓取用户访问平台下的用户访问请求、响应等流量信息[4]。本研究以字符串的形式存储访问者请求数据。网络攻击人员采用GetShell、XSS注入等方式开展渗透操作时,会将固定框架语句写入目标码、URL内。本文提出的基于深度学习的网络流量入侵检测方法的原理为针对不同特征维度选取对应的关键词,并对关键词出现频率进行记录,从而抓取框架中数据特征。通过特征转化,能够将字符串转变为矩阵形式,便于机器理解和操作,为构建网络流量入侵检测模型提供了保障。深度学习下网络流量入侵检测方法的关键词特征详见如表1所示。
1.2 数据初处理
在提取字符串特征结构时,可以应用关键词维度统计(KDS) 处理法。KDS法对One-Hot离散文本语义特征提取法、词袋文本特征提取法进行了融合,将两种提取法的核心技术充分发挥出来,可以对专项特征进行针对性的提取,创新了入侵检测方向的特征提取思路和方式。KDS法可以在无序长字符数据中对关键特征进行提取,形成满足学习模型的数据信息,具有降低冗余数据、改善算法模型运行效率的优势。本入侵检测模型可以利用KDS处理法,实现无规则字符串数据向结构化数据的转变,有效统计各维度的词量,充分体现不同流量包的结构差别,以便带入算法模型中进行运算,促进网络流量入侵检测模型的构建和学习。在KDS处理法的保障下,可以有效整合模型各项功能,例如:统计分析、匹配及关键词对比等,进一步优化数据处理方式,以监督学习的形式提取数据特征,获得较优的数据特征匹配结果,有效消除冗余数据,保障算法模型的运行速率[5]。具体流程如下:
1) 在特征层中将各关键词看作独立特征,通过向量格式编排特征层数据,表达式为:[features=selectunionnull......root]。
2) 将上述表达式进行映射处理,设定特征层第n个关键词为[Xn],得到映射层表达式:[X=X1X2X3......Xn]。若第n个特征出现的标记为[Cn],出现频率计数为[Cn],借助公式对各条网络流量中关键词的出现频率进行统计,得到[Cn=i=1(cni)],最终特征向量表达式为:[Hn=C1C2C3......Cn]。
3) 完成数据实例转化对比,建立包括未经处理数据、KDS法处理后数据的转化表,调整数据格式如表2所示。
1.3 数据压缩与数据降维处理
本研究方法结合自编码器的稳定特征学习性能,对网络流量数据主成分进行提取,完成数据的压缩、降维处理,有效避免了噪声数据和冗余数据的影响,增强了算法的监测效率。自编码器神经网络模型建立在无监督算法的基础上,由输入、隐藏和输出三层结构组成,其中输入和输出层的节点数相同。若输入向量为[x=x1, x2 x3 ... xn],隐藏层编码处理公式为:[h=σ(Wx+b)]。
数据压缩处理结果为[h=h1, h2, h3 ... hn],W为输入层、隐藏层间的权重值,[σ(∙)]为激活函数,b为偏置值。
通过输出层进行数据解码,得到公式:[x=σ(W'h+b')]。其中,偏重、偏置量分别是W'、b',输出结果是[x]。针对隐藏层输出结果进行还原处理,还原为原始输入数据,并开展降维操作,由此增强入侵检测模型性能。采用逐层贪婪训练法,自编码神经网络可以对数据开展预训练,应用BP神经网络调整网络模型。而鉴于本研究方法将极限学习机、单隐藏层自编码器进行了整合,所以需要预训练自编码器,确定输入层到隐藏层间的初始权重,通过随机梯度下降算法和BP神经网络,得出隐藏层的最优输出权值和损失函数的最小值。
2 实验过程
2.1 基于深度学习的网络流量入侵检测系统模型
在构建网络流量入侵检测系统模型时,将AE自编码器、极限学习机整合起来,针对AE-ELM神经网络中超学习参数对算法模型产生的影响及存在的缺陷,引入改进后的粒子群优化算法(POS) ,借助优化PSO搜索最优化模型学习参数,建立PSO-AE-ELM模型,实现多维数据处理以及对样本数据深层特征的有效提取,维去噪,缩短训练时间[6]。针对深度神经网络的PSO-AE-ELM预测模型,可以进行入侵检测识别的预测,借助粒子群优化算法探寻最优自编码ELM的隐藏层神经节点数量,明确偏差值、权重以及激活函数,结合最优结果、训练样本,并在模型中导入预测结果,开展实验验证。实验验证流程具体如下:
1) 针对自编码器搜集的网络流量数据,开展数据降维处理操作,优化网络流量入侵检测模型运行效率。
2) 将整合极限学习机和自编码器(AE-ELM) 的神经网络作为预测模型,在重构模型内输入数据集合,通过随机梯度下降法(SGD) 对自编码器进行训练,提取AE神经网络特征。依托PSO算法找到最优AE-ELM超学习参数,结合优化结果明确隐藏层神经节点的数目,获取各项参数数值。其中,AE-ELM神经网络下的超学习参数直接影响着算法模型的性能,具体指的是进行模型训练时在深度学习中设定的参数,包括:隐藏层数目、梯度下降法循环数、学习率及隐藏层单元数等。
3) 将实际网络入侵数据导入通过最优参数构建的POS-AE-ELM模型中,结合准确率判定优化后的模型检测精准度。
2.2 入侵检测模型优化实现过程
POS-AE-ELM模型的优化实现过程详见图1所示。
结合图1,POS-AE-ELM模型优化过程具体介绍如下:
1) 针对互联网端的行为流量,利用蜜罐系统进行搜集和存储,划分和标注行为流量的供给类型,形成原始数据集,并进行进一步处理获得显性结构数据,有序进行数据的过滤、类型转变及归一化操作,使实验样本达到学习模型的标准要求。
2) 按照比例划分实验样本数据,分别形成测试集和训练集。结合训练集建立AE-ELM网络流量入侵检测模型,而利用测试集则能够检验模型精确程度,分析模型检测准确率函数的有效性。准确率函数指的是开展机器学习算法检测测试数据时,应用Classification-report函数进行测试的准确率运算输出。
3) 利用基准粒子群优化算法对AE-ELM模型的学习参数进行优化,并参考准确率函数形成适应度函数,明确适应度值。在得到POS-AE-ELM模型相关参数的基础上,确定最优学习参数和优化模型,获得最优超学习参数组合,即最优超学习参数。
2.3 模型框架结构
基于粒子群优化算法下,种群粒子趋近于最佳粒子位置时,粒子速度接近0,会影响种群多样性,致使种群粒子无法摆脱局部最优,不利于精细局部搜索工作的开展。本文算法以标准PSO为基础,借鉴遗传算法的变异操作,引入动态惯性权重,形成改进的粒子群优化算法。该算法可有效识别检测目标类别,避免种群粒子过早收敛[7]。结合多超学习参数分析结果,也能够通过下述方式进一步提升模型入侵检测性能。一方面,可以将全局搜索视作外部优化层,对改进后粒子优化算法模型的最优特征粒子进行选择,借助AE-ELM模型的适应度函数对特征粒子进行评估;另一方面也能将局部搜索视作内部优化层,参考遗传算法的变异操作,在粒子群优化算法中融入动态权重值的概念,在增加迭代次数的过程中实现对PSO局部化优化,以此来合理选择局部特征,有效克服标准PSO算法容易陷入局部最优的问题,实现全局优化。其中,局部搜索、全局搜索是考察算法性能的两大指标,前者指的是无穷接近最优解的能力,依赖于对解空间进行按邻域搜索;后者指的是探寻全局最优解位置的能力,可以从最优解中选择最好结果作为最终结果。POS-AE-ELM模型框架结构详见如图2所示:
检测网络入侵流量前,首先要初始化改进PSO算法的相关参数,在给定范围内随机生成20个初始粒子形成种群。然后迭代优化多次,用适应度函数评价各粒子,更新粒子位置和速度,直到满足迭代停止条件。最后将全局最优粒子位置对应的参数组合代入POS-AE-ELM模型,完成模型训练。
3 实验结果分析
3.1 实验环境及数据
搭建POS-AE-ELM模型测试实验环境如表3所示:
实验中,PSO-AE-ELM模型的参数设置如下:种群粒子数20,最大迭代次数200,适应度函数为分类准确率。
结合实际项目所采集的网络流量数据,将蜜罐系统部署在服务器或私有云等多节点中,发挥监控系统的捕捉模块功能来搜集网络流量数据,这些数据均具有单个标志属性和三个特征属性,属于正常行为流量[8]。针对流量数据开展拆分解析,设定相应标签,确定网络流量入侵检测原始样本数据。鉴于网络流量数据无规律且波动变化较大,可以应用min-max归一化法对特征参数进行压缩,使参数处在[0,1]的范围。网络流量数据的初始值为x,xmax为数据组内最大值, xmin为数据组内最小值,归一化处理公式表示为:[x'=x-xminxmax-xmin]。