基于Transformer 的煤矿爆破块度分析
作者: 鹿丙振 安文勇 吴长伟
摘要:准确量化爆破后岩石的破碎程度对于优化爆破设计和提高采矿作业的生产效率至关重要。传统的图像分析方法通常耗时耗力,且准确性较低。文章提出了一种名为BBDFiT的框架,能够自动分析爆破后图像中的岩石破碎分布。BBDFiT可以高效提取岩石块度分布和内部裂隙结构,为优化爆破设计和质量控制提供数据驱动的见解。在专用的煤矿爆破块度数据集上,BBDFiT实现了81.5%的top-1准确率,比当前最先进的视觉转换器模型高出约1.8%,而推理速度相当。这种人工智能驱动的方法为采矿企业提供了一种新的数字化工具,有望提高生产效率和经济效益,在矿山工程图像分析领域具有广阔的应用前景。
关键词:Transformer;爆破设计;图像分析;煤矿爆破块度;矿山工程
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)27-0023-04
1 背景
近年来,采矿业与多学科技术融合,推动了矿山智能化建设。实现对露天矿爆破效果的实时智能评价需要自动、快速且准确地统计爆破后大块率[1-3]。由于传统人工目视统计大块率效率和精度较低,研究人员提出了利用图像分割算法自动统计爆破后大块率的新方法[4],该方法已在多个矿山现场得到广泛应用。
在过去十年中,计算机视觉领域主要采用了基于卷积神经网络的深度神经架构[5-6]。不同于此,Transformer 是一种主要基于自注意力机制的神经网络,可处理特征之间的关系。Transformer被广泛应用于自然语言处理(NLP) 领域,如著名的GPT-3模型[7]。为将Transformer 结构用于视觉任务,研究人员探索了如何表示来自图像和视频数据的序列信息。Dosovitskiy 等人[8] 开发了Vision Transformer(ViT),通过将图像分成局部patches作为视觉序列输入,如今,Transformer已广泛应用于图像识别[9-10]、目标检测[11]和图像分割[12-13]等任务。
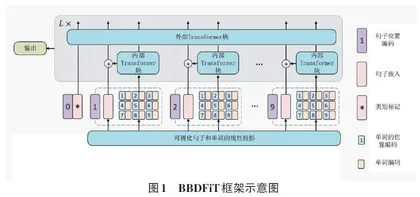
现有工作在处理复杂多样的自然图像时可能显得过于简单。因此,本文提出了一种新的Transformer架构——Blast Block Detection Frame⁃work in Transformer (BBDFiT),如图1 所示。该方法首先将输入图像分割为较大的“视觉句子”,再将每个句子进一步分割为较小的“视觉词”。除常规Transformer块用于捕捉句子级特征外,本文还嵌入了子Transformer模块,以细致挖掘视觉词的细粒度特征。通过这种分层表示,BBDFiT能够提取更加细致和丰富的视觉信息。
实验结果显示,与Transformer网络相比,该模型在ImageNet 及下游任务上表现更优。本文提出的BBDFiT在精度和计算效率之间取得了更好的平衡。在采矿领域,BBDFiT架构为高效分析煤矿爆破残渣图像提供了新的可能。
2 方法
2.1 爆破块度检测架构
给定一张二维图像,本文将其均匀分割为n 个patch ℵ = [ X1,X2,...,XN ]ϵRn × p × p × 3,在ViT[8]模型中,这些图像被划分成多个patch,每个patch都具有固定的分辨率( p,p)。本文提出了Blast Blockiness DetectionFrame in Transformer(BBDFiT)架构,用于学习煤矿爆破块度分析图像中的全局块度和局部块度信息。在BBDFiT中,本文将一个patch定义为代表煤矿爆破块度图像的视觉句子。随后,再将每个patch进一步分割为m 个子patch,即一个视觉句子Xi 由一系列视觉单词(子patch) 组成:
Xi → [ xi,1,xi,2,...,xi,m ] (1)
式中:xi,j ϵRs × s × 3 为第i 个视觉句子的第j 个视觉单词,(s,s) 为子patch的空间大小,j = 1,2,...,m。通过线性投影,本文将视觉词Y i转换为一系列词嵌入:
Y i → [ yi,1,yi,2,...,yi,m ] (2)
yi,j = FC (Vec(xi,j )) (3)
公式(3) 中,yi,j ϵRc 为第j 次词嵌入,c 为词嵌入的维数,Vec(∙)为向量化运算。
在BBDFiT中,本文设计了两个数据流,其中一个流用于处理视觉句子,另一个流用于处理每个句子中的视觉单词。对于词嵌入,本文使用Transformer块来探索视觉词之间的关系:
Y il′ = Y il - 1 + MSA(LN (Y il - 1 )) (4)
Y il = Y il′ + MLP (LN ( Y il′ )) (5)
其中,l = 1,2,...,L 为第L 个块的索引,L 为堆叠块的总数。第一个区块的输入Y i0 即为公式(2)中的Y i。
变换后图像中的所有词嵌入γl = [Y 1 l ,Y 2 l ,...,Y nl ]可以看作是一个内部Transformer块,表示为Tin。这个过程通过计算任意两个视觉词之间的相互作用来建立视觉词之间的关系。
对于句子级,本文创建句子嵌入记忆ℶ0 来存储句子级表示序列:ℶ0 = [ Zclass,Z10,Z20,...,Zn0 ]ϵR(n + 1) × d。其中,Zclass 为类令牌,与ViT[8]类似,均初始化为0。在每一层,通过线性投影将词嵌入序列转换到句子嵌入域,并加入句子嵌入中:
Zil - 1 = Zil - 1 + FC (Vec(Y il )) (6)
式中,Zil - 1ϵRd 和全连通层FC用于使维度匹配加法。通过上述加法运算,句子嵌入ℶl 的表示得到了词级特征的增强。本文使用标准的Transformer块来转换句子嵌入:
ℶ′l = ℶl - 1 + MSA(LN (ℶl - 1 )) (7)
ℶl = ℶ′l + MLP (LN ( ℶ′l )) (8)
综上所述,BBDFiT块的输入和输出包括如图1所示的视觉词嵌入和句子嵌入。因此,BBDFiT可以表示为:
γl,ℶl = BBDFiT (γl - 1,ℶl - 1 ) (9)
在本文的BBDFiT块中,该模型采用了分层结构:内层Transformer块用于挖掘patch内部的局部特征,而外层Transformer块则聚焦于捕捉不同patch之间的全局关联。通过L 次堆叠这种分层BBDFiT模块,模型能够高效地融合局部和全局视觉信息,从而构建一个Transformer-Transformer 网络。最后,使用分类令牌作为图像表示,并通过全连接层进行分类处理。本文为句子嵌入和词嵌入添加了位置编码,以保留空间信息。如图1所示,使用了可学习的一维位置编码。每个句子ℶ0被分配了一个位置编码:
ℶ0 ← ℶ0 + Esentence (10)
其中,句子Esentence ϵR(n + 1) × d 为句子被分配位置编码,句子中的每个视觉词也被分配位置编码,在每个词Y i0 嵌入中加入一个词位置编码,以确保模型能够保留和利用空间信息。
Y i0 ← Y i0 + Eword,i = 1,2,…,n (11)
其中,单词位置编码Eword ϵRm × c 是跨句子共享的。这样,句子位置编码用于保持全局空间信息,而单词位置编码用于保持局部相对位置信息,两者编码相互补充。这种设计确保了模型在处理视觉信息时,既能捕捉到整体的空间布局,又能关注到局部的细节关系。
2.2 网络体系结构
本文在ViT[8]的基本配置上构建了BBDFiT架构。图像的patch 大小设为16 × 16,每个patch 被划分为m = 4 × 4 = 16 个子patch。表1 列出了BBDFiT 的3 种不同模型尺寸变体,分别是BBDFiT-S、BBDFiT-B 和BBDFiT-L。这3种模型规模不同,参数量分别为6.1 M、23.8 M和65.6 M。在处理224×224分辨率图像时,对应的计算量(FLOPs) 分别为1.4 B、5.2 B 和14.1 B。
在模型名称中,Ti表示Tiny(很小),S表示Small (小),B表示Base(基础)。FLOPs的计算是基于输入图像分辨率为224 × 224。
3 实验与分析
本文的实验基于采集到的爆破作业过程视频数据集。数据集包含37个时长为一分钟的爆破作业视频,整体大小为2.16 GB,涵盖多个拍摄角度,包括爆破现场后现场石块的左侧、右侧、正前方以及左下方、右下方等。经过抽帧、打标签等预处理后,共获得大小为5.86 GB的58 617张图片数据的数据集。
根据表2可知,训练集包含40 570张爆破现场石块图片,涵盖多个拍摄角度;测试集则包含12 047张爆破现场石块图片,也覆盖了这些拍摄角度。
3.1 参数设置
训练参数的设置如表3 所示:学习率(LR) 设为0.01,批大小(batch size) 为16,训练次数(epochs) 为300,初始权重使用ViT 的原始权重,训练设备为GPU。
3.2 实验内容
本文通过对不同数据集和模型进行组合,验证自建数据集和模型的有效性。实验设置遵循控制变量原则,组合方式如下:1) 公开数据集+模板匹配模型;2) 自建数据集+模板匹配模型;3) 自建数据集+BBDFiT模型。
根据以上组合方式,本文设计了两个对照实验:1) 比较公开数据集+模板匹配模型与自建数据集+模板匹配模型,以验证自建数据集在提升实际应用中识别率方面的有效性;2) 比较自建数据集+模板匹配模型与自建数据集+BBDFiT模型,以验证BBDFiT模型的有效性。
3.3 实验结果分析
3.3.1 数据集训练模板匹配模型对比
本研究评估了BBDFiT模型在NVIDIA V100 GPU 和PyTorch环境下、输入尺寸为224×224时的推理速度性能。结果表明(见表4) ,与ViT 和DeiT 相比,BBDFiT在相似的推理速度下获得了更高的准确率。虽然BBDFiT块增加了一些计算和内存开销,但增幅有限,它能够有效捕捉局部结构信息,在精度和复杂度之间取得了更好的平衡。
3.4 消融实验
3.4.1 位置编码的影响
位置信息对图像识别至关重要。在BBDFiT结构中,句子位置编码用于保留全局空间信息,而词位置编码则保持局部相对位置信息。实验验证了它们的有效性(见表5) 。在使用两种位置编码时,BBDFiT-S 取得了81.8%的最佳top-1准确率。移除句子位置编码或词位置编码后,准确率分别下降了0.8%和0.7%。若去除所有位置编码,则准确率严重下降1%。结果表明,BBDFiT中的位置编码方案能够很好地融合全局和局部位置信息。
3.4.2 头部个数
在本文中,外部Transformer块采用了64的头宽度。而内部Transformer块中的头数量则是另一个需要研究的超参数。通过表6中的评估结果可以看出,适当的头数量(例如2或4) 可以达到最佳性能。
3.4.3 视觉单词的数量
在BBDFiT 中,输入图像被分割成若干个16 × 16patch,每个图像patch 进一步划分为m 个子patch(也可称为视觉单词),其大小为(s,s),以增加计算效率。本文测试了超参数m 对BBDFiT-S结构的影响。当调整m 时,嵌入维度c 相应调整以控制FLOPs。根据表7的结果显示,m 的变化对性能产生了轻微影响。本文默认使用m = 16来提高其效率。