Python语言常用内排序算法的研究
作者: 李毅 陈巧琳 胡春兵 刘凯峰
摘要:内排序算法在计算机程序设计中经常被用于解决实际问题,因此研究内排序算法具有重要的理论意义和广泛的应用价值[1]。从时间复杂度、空间复杂度及稳定性方面进行分析。该文具体分析了Python语言中几种常见的内排序算法,并对这些内排序算法的基本思想、算法代码、执行过程进行了详细的介绍。方便初学者对排序算法有一个全面深入的了解。
关键词:内排序算法;时间复杂度;空间复杂度;稳定性;Python语言
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)23-0101-03
Python语言是最近几年来非常火爆的语言。在人工智能、深度学习、模式识别、数据分析、科学计算、工业自动化、引力波探测等众多领域,都可以看到Python语言的身影。无论是热爱编程的中小学生,还是在探索人类知识边界的一流科学家都在使用Python语言[2]。
随着计算机的快速发展及应用领域的不断扩大,由于现阶段计算机硬件的速度和存储空间比较有限,故软件设计人员一直把提高计算机硬件速度和节省存储空间作为重点研究方向[3]。其中,排序算法已被程序设计人员纳为主要考虑的因素之一。合理的排序算法将大大提高影程序的执行效率同时减少存储空间的占用量,甚至影响整个软件的综合性能。所谓数据排序,就是将一组无序的数据,按照其关键字的大小,递增或递减地排列成一个有序的序列[4]。
1 排序算法的分类
在Python语言学习过程中,经常会碰到关于字符、字符串、整数以及浮点数的排序问题。根据排序表中记录数据量n的不同,排序过程需要的存储空间也有所不同,故将排序算法分为外排序算法和内排序算法两大类。外排序算法是指待排序数据量非常大,计算机的内存空间不能一次性容纳全部记录,在排序过程中需要进行数据内、外存交换[5]。内排序算法是指待排序数据在计算机随机存储器RAM中进行的排序过程,其过程不涉及数据的内外交换。常用的内排序算法有:希尔排序、快速排序、归并排序、冒泡排序、简单选择排序、简单插入排序等。接下来本文就通过具体的实例,对这些常用内排序算法的基本思想、执行过程、算法代码、时间复杂度、稳定性进行逐一分析、归纳、总结。
2 部分常用内排序算法具体分析
2.1 冒泡排序
2.1.1 基本思想
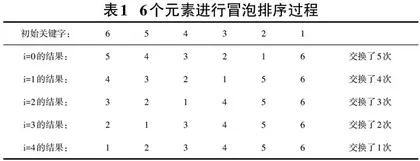
冒泡排序一种典型的交换排序方法也被称为气泡排序,冒泡排序基本思想是数据表中无序区中相邻元素关键字的比较和元素位置的交换使关键字较小或关键字较大的元素如气泡一样逐渐往上“漂浮”直至最终露出“水面”的过程。如此往复,最终完成排序。冒泡排序过程中,假如是对[n]个数进行排序,则需要进行[n-1]轮,每轮进行[n-1-i]次元素关键字的比较。
2.1.2 算法代码
例:对列表R=[6,5,4,3,2,1]的元素从小到大进行排序。
该例子用冒泡算法实现代码片段如下:
def BubbleSort(R):
n=len(R)
for i in range(n-1):
count = 0
for j in range(0,n-1-i):
if R[j]>R[j+1]:
R[j],R[j+1]=R[j+1],R[j]
count+=1
if 0==count:
return
2.1.3 执行过程
每次从无序区中冒出一个关键字最大的元素并将其归位。冒泡排序每轮产生的有序区是全局有序区并且有序区中的所有元素都是归位的。初始时将全局有序区看成空,所有[i]从0开始排序。
2.1.4 算法分析
1最好情况分析
如果初始排序表是正序,则在第1趟排序后结束,所需要的关键字比较和元素移动次数均达到最小值[Cmin]和[Mmin]。
两者合起来为[O(n)],因此冒泡排序最好情况下的时间复杂[O(n)]。
2最坏的情况分析
若初始排序表反序,则需进行[n-1]趟排序,每趟排序需要进行[n-i-1(0≤i≤i-2)]次关键字的比较, [3(n-i-1)]次元素的移动(一次交换为3次移动)。反序时冒泡排序算法的关键字比较次数和元素移动次数均达到最大值[Cmax]和[Mmax]。
两者结合起来为[O(n2)],因此冒泡排序最坏情况下的时间复杂度为[O(n2)]。
3平均情况分析
平均情况的时间复杂度分析要稍微复杂很多,因为算法可能在中间的某一趟排序完成后就结束,但是平均的排序趟数仍是[O(n)],每一趟的比较次数和元素移动次数为[O(n)],所以平均时间复杂度为[O(n2)]。由于冒泡排序算法平均时间性能接近最坏的时间性能,故冒泡排序算法是一种低效的排序方法。
由于在冒泡排序算法中只使用了固定的几个辅助变量,与数据规模n无关,因此算法的空间复杂度为[O(1)],冒泡排序就是一个就地排序算法。对于任意两个满足[i<j]且[Ri=R[j]]的元素,两者没有逆序,不会发生交换,也就是说[R[i]]和[R[j]]的相对位置保存不变,所以冒泡排序算法是稳定排序算法。
2.2 简单插入排序
2.2.1 简单插入排序基本思想
在一个数据表中每次将无序区中一个待排序元素按照其关键字或大或小插入有序区中合适位置。先比较数据表中前两个相邻数据,按其关键字大小排序,形成有序区。接着每次从无序区中取出第一个元素,按照其关键字大小将其插入到有序区中最合适位置,使有序区中元素仍然保持有序,直到无序区中全部元素被插入到有序区中为止。
2.2.2 算法代码
例:对于列表R=[66,55,44,33,22,11]的元素从小到大排列
该例子用简单插入排序算法实现代码片段如下:
def InsertSort(R):
for i in range(1,len(R)):
if R[i]<R[i-1]:
tmp = R[i]
j=i-1
while True:
R[j+1]=R[j]
j=j-1
if j<0 or R[j]<=tmp:
break
R[j+1]=tmp
return
2.2.3 执行过程
简单插入排序每趟产生的有序区是局部有序区(初始时将[R[0]]看成局部有序区,所以[i]从1开始排序),局部有序区中的元素并不是一定放在最终位置上,在后面的排序中可能发生元素位置的改变,当一个元素在排列结束前就已经放在其最终位置上将其称为归位。相应地全局有序区中的所有元素均已归位。
2.2.4 算法分析
简单插入排序是由两重循环构成的,对于具有[n]个元素的顺序表R,外循环表示要进行[n-1]趟排序。在每一趟排序中,当且仅当待插入元素[R[i]]小于有序区的尾元素时才进入内循环,所以简单插入排序的时间性能与初始排序表相关。
1最好情况分析
如果初始数据表按关键字正序,则在每趟[R[i](1≤i≤n-1)]的排序中仅需进行一次比较,由于比较结果是正序,这样每趟排序均不进入内循环,故元素移动次数为0。正序时简单插入排序的比较次数和元素移动次数均达到最小值[Cmin]和[Mmin]。
2最坏情况分析
如果初始排序表按关键字反序,故在每趟[R[i](1≤i≤n-1)]的排序中,由于tmp均小于有序区中的所有元素,则需要[i]次关键字比较,同时有序区中的每个元素后移一位,再加上前面[tmp=R[i]]和[Rj+1=tmp]的两次移动,需要[i+2]次移动。由此可见,反序时简单插入排序的比较次数和元素移动次数均达到最大值[Cmax]和[Mmax]。
两者结合起来为[O(n2)],故简单插入排序算法最坏时间复杂度为[O(n2)]。
3平均情况分析
在每趟[R[i](1≤i≤n-1)]的排序中,平均情况是将[R[i](1≤i≤n-1)]插入有序区的中间位置,这样平均比较次数为[i/2],平均移动次数为[i/2+2],对应的[Cavg]和[Mavg]。
两者结合起来为[O(n2)],故简单插入排序算法平均情况下的时间复杂度为[O(n2)]。由于简单插入排序算法的平均时间性能接近最坏性能,所以是一种低效的排序算法。
简单插入排序算法中只使用了[i、j]和[tmp]共三个辅助变量,与数据规模[n]无关,故算法的空间复杂度为[O(1)],也就是说简单插入排序算法是一个就地排序算法。简单插入排序算法也是稳定排序算法同冒泡排序算法一样。
2.3 简单选择排序
2.3.1 基本思想
简单选择排序算法的基本思想是每次从无序区中选出关键字最小或者最大的元素,按顺序排放在有序区的最后。假如从第[i]趟排序开始时,当有序区为[R[0..i-1]],无序区为[R[i..n-1](0≤i≤n-1)],则第[i]趟排序是从无序区中挑选出关键字最小或者最大的元素[R[k]],并将[R[k]]与[R[i]]交换,使[R[0..i]]成为新的有序区[R[i+1..n-1]]成为新的无序区。这样不断扩大有序区,缩小无序区,直到全部元素有序为止。
2.3.2 代码实现
例:对于列表R=[18,17,19,8,11,13,12,14]的元素从小到大排列
该例子用简单选择排序算法实现代码片段如下:
def SelectSort(R):
for i in range(len(R)-1):
min_index = i
for j in range(i+1,len(R)):
if R[min_index]>R[j]:
min_index = j
R[i],R[min_index]=R[min_index],R[i]
return
2.3.3 执行过程
简单选择排序每趟产生新的有序区都是全局有序,有序区中所有元素都是归位了。
2.3.4 算法分析
无论初始排序表的顺序如何,在第[i]趟排序中找出无序区中的最小元素,内[for]循环需要做[n-i-1]次比较,故总的比较次数为[Cn]。
元素移动次数,当初始排序表正序时,移动次数为0,反序时每趟排序均要执行交换操作,此时元素总的移动次数为最大值[Mmax=3(n-1)]。然而,无论初始排序表如何分布,所需的元素比较次数都相同,故简单选择排序算法的最好,最坏及平均时间复杂度均为[O(n2)]。同冒泡排序算法与简单插入排序算法相比,简单选择排序算法中元素移动次数是最少的。
简单选择排序算法中只使用了固定的几个复杂变量,与数据规模[n]无关,故简单选择排序算法与冒泡排序算法、简单插入排序算法一样是一个就地排序算法,空间复杂度为[O(1)]。另外,简单选择排序算法是一种不稳定的排序算法。
3 各种内排序算法的比较和选择[6,7,8]
除了上述分析的三种常见的排序算法外,还二路归并排序、希尔排序、堆排序、快速排序、折半插入排序等,下面对这些内排序算法进行逐一细致的总结。