基于知识图谱的食疗养生知识问答系统的设计与实现
作者: 马莉 刘静海 肖楠桦 张妮
摘要:随着社会进步,人们的健康意识不断增长,“保温杯里泡枸杞”反映了全民保健的一种常态。该文以网络上丰富的食疗养生信息为知识获取来源,利用爬虫技术从网页上获取数据,通过数据处理、知识融合、数据可视化等过程构建基于食疗知识的知识图谱。并以此为基础,构建问答系统,该问答系统通过特征词表、问句模板库进行问句解析理解用户的自然语言问句,构建cypher语句对知识图谱进行查询,通过答案生成模块将准确的答案返回给用户,满足用户对于食疗养生知识的问答需求。
关键词:知识图谱;问答系统;养生
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)24-0056-04
1 引言
为了使网络中的数据与信息具备“语义化”特征而方便机器理解,知识工程经历了“语义网”“本体”“知识图谱”三个载体。知识图谱由百度公司2012年提出,当时的目标是为了优化引擎搜索质量,提供用户高查询体验质量。随着智能化时代的到来,知识图谱逐渐成为人工智能的最高阶段——认知智能的一个必备工具,在人工智能(AI) 中扮演着大脑的角色。有关知识图谱的应用也层出不穷,其中问答系统目前最流行的应用。基于知识图谱的问答系统能够理解用户输入的自然语言问句,再通过知识图谱中的实体、关系等查找准确的答案返回给用户,从而提高信息搜索的效率。
现如今,越来越多的学者开始构建知识图谱,面向疾病、医药等方向的知识图谱层出不穷,比如,美国国立医学院开发的一个较完整的医学知识库UMLS[1],它为医学领域的发展带来极大的便利。阮彤[2]等人通过对现有医疗知识图谱的分析和探索,构建了中医药知识图谱。昝红英[3]等人构建了涵盖了8772种症状的中文症状知识库,李俊卓[4]等人构建了儿科疾病及保健知识的知识图谱,但关于食疗养生知识这一领域的知识图谱并不多。近年来,人们对健康的意识日益增长,对食疗养生知识的需求也越来越强烈。本文将研究食疗养生领域知识图谱构建,并实现基于该知识图谱的问答系统,满足人们对养生知识的获取的需求。
2 研究现状
国外问答系统的研究比较早,最早出现的问答系统是Weizenbaum在1966年设计的问答机器人ELIZA,它能扮演心理专家的角色,帮助精神病患者进行心理治疗;IBM的Waston系统在2011年的Jeopardy问答竞赛中击败了人类最优秀选手获得冠军引起了业界的大量关注,在Waston系统设想的框架中用到了几乎所有的自然语言处理技术来帮助知识获取以及自动问答;Minsuklee等人研发的MedQA[5]系统是一个面向医生的医疗问答系统;MEANS[6]系统是一种基于语义技术的问答系统,但只能回答几类问题的范围十分有限,十类问题只能回到其中四类。AskCuebee[7]是专门针对寄生虫知识的问答系统,它不把问题局限于特定的集合或模板。除此之外,苹果公司 Siri、Google Now、微软 Cortana移动生活助手也是基于问答系统技术开发的软件。
问答系统按照领域可分为开放领域和限定领域两大类。基于开放领域的能够问答用户的各种各样问题,一般要用到信息检索、信息抽取和自然语言处理等技术,目前已有一些常用的数据集如SQuAD、TriviaQA、CuratedTREC、WebQuestions等。在国内,曹明宇[8]等从医学指南及SemMedDB知识库中抽取出三元组,构建原发性肝癌知识图谱,再在此基础上,利用模板匹配的问句处理方法开发了原发性肝癌问答系统。贾李蓉[9]等人构建了一个基于中医药学语言系统的知识问答系统,该系统可以通过信息搜索功能找出相似度高的病案从而为用户提供辅助诊疗建议。医疗健康一直是研究的热点,在这方面不少学者已经取得一些成果。但目前国内对食疗养生的问答系统研究还比较少,因此,本文设计基于知识图谱的养生知识问答系统具有较强的实用性,能够帮助用户迅速查找食疗养生知识。
3 食疗养生知识图谱构建
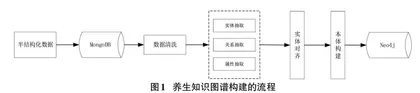
目前广泛运用的知识图谱的构建方法主要有两种:自底而上的构建方法和自顶而下的构建方法。自底向上指的是从数据源中取出实体,然后经过选择加入到知识图谱,再构建本体层的模式,一般通用领域的知识图谱采用此种方式。自顶向下是指先定义好知识图谱的本体数据模式,再将实体加入知识图谱中,特定领域知识图谱的构建对领域知识的深度和精度有很高的要求,需要先构建本体层[10]。本文的知识图谱是面向特定领域,所以采用自顶而下的构建方法进行构建。即从拥有半结构化的数据网站上获取数据源,随后进行知识抽取、本体构建等操作,得到健康养生的知识图谱。知识图谱构建的流程图如图1所示。
3.1 模式层构建(本体部分)
模式层是知识图谱的顶层设计,也可以说是知识图谱的骨架,在工业领域称之为schema,包含了这个领域中有意义的实体以及这些实体的关系。本文采用自顶向下的方式构建知识图谱,选定“寻医问药网”的食疗养生模块为数据获取的来源,最后确定了食疗养生知识图谱的模式层所需要实体、实体属性和关系类型。
实体的六大类别为:疾病、功效、料理、人群、季节、食材,如表1所示。
实体之间的关系如表2所示。
3.2 数据层构建
1) 数据来源
问答系统的质量与知识图谱的质量息息相关,知识图谱质量最重要的影响因素就是数据源的质量,因此在选择数据源时要尤为慎重,综上所述,通过对多种数据源的对比,本研究主要选择了寻医问药网(https://www.xywy.com/) 中的食疗养生模块作为本知识图谱的数据来源,除此之外还选择了其他具有相关数据的半结构化的网站,半结构化数据能在一定程度上节省构建知识图谱时数据处理的时间。
确定数据源后,首先对寻医问药网中食疗养生模块中的网页内容结构进行解析,本文主要采用lxml对网站进行解析,它能够提供一些函数用来处理导航、搜索、修改分析书等功能。它能将复杂的HTML文档转换成一个复杂的树形结构,每个结点都是Python对象。从网站页面下div模块下获取数据,利用Python编写爬虫脚本对“寻医问药网”下的“食疗健康”网页进行数据爬取,最后将爬取下来的信息以Json字符串格式插入到MongoDB数据中[11]。
爬取下来的数据不是完全满足知识图谱的数据,还要对信息进行清理,为图谱构建做准备。比如一些错误信息要进行过滤,还有一些混合信息要进行拆分,有一些信息要进行提取。比如料理的推荐食用时间一般都是几个时间的组合,中间用竖线隔开,需要对字符串进行处理,提取出具体的时间再存储到Neo4j知识图谱当中。除此之外本文还使用正则表达式与split函数对原始数据进行清理。
2) 知识融合
多样性的数据来源能丰富了知识图谱的数据量,但也带来了数据信息冗余、知识间关联不够明确等问题。如从不同的网站抓取的数据源存在一些相同的信息,这是信息冗余;一种疾病名称有简写和详细的表达方式,这是知识间的关联不明确。为了保证融合的有效性,需要结合知识融合技术对数据进行处理,即合并两个知识图谱。本文利用规则和实体对齐方法构建了一套疾病别名实体库,并在此基础上通过实体映射融合多源数据。
3) 图谱的存储与可视化
目前常用的存储知识的方式有三种,三元组形式的RDF存储、关系型数据库存储和图数据库存储。本项目结合实际情况,使用目前主流的Neo4j图数据库作为知识图谱数据的存储数据库,Neo4j拥有图数据的高性能、高可靠性、高可扩展性等优势。
将数据导入后即可获得如图2所示的知识图谱,该知识图谱一共拥有29293个实体节点,121112条关系。
从图2可以看出,知识图谱中的实体拥有不同的颜色代表不同的含义,例如标注a的代表功效,标注b的代表食物,标注c的代表疾病,实体之间通过关系线连接在一起,这样的界面更能让用户理解实体间的关系。
4 问答系统构建
本问答系统主要满足用户对于食疗养生知识的问答需求,即用户用自然语言输入有关食疗养生的问句,系统通过分析处理后将该问题的准确答案反馈给用户。问答系统的构建主要包括以下6个流程:问句输入、问句预处理、问句分类、图数据库查询、答案模板匹配及答案生成。如图3所示。
4.1 问句预处理
问句预处理是对输入的问句进行清洗、分词、词性标注以及去停用词。本文采用Python提供的Jieba包对问句进行分词处理,将问句分解为一个个符合逻辑的词语。
4.2 问句分类
根据用户对养生方面的需求,以及对如“百度知道”问答平台中一些用户对养生咨询所提问题进行整理分析,最终整理出十四类问题,具体问题类型如表3所示:
在构建知识图谱的过程中的预处理过程中已经构造好食疗养生特征词库,通过actree算法进行匹配后的特征词传入问句类型字典,得到与特征词相匹配的词类型,然后再根据提前构建的问句类型库,找到特征词对应的词类型问句分类集合,判断问句属于哪种类型。
4.3 问句解析
问句解析部分是根据问句分类得到的问句类型,编写出对应的cypher查询语句模板到知识图谱中进行查询,查询到结果时将答案集合输出给用户。cypher是描述性的图形查询语言,拥有语法简单、功能强大的特点,类似于关系型数据库的SQL。
如针对关于问句类型为“由疾病推荐食物”的查询语句模板如下所示:
elif question_type == 'disease_food':
Sql=["MATCH (m:disease)-[r:disease_eat]-(n:eat) where m.name='{0}' return
m.name,n.name,n.name1,n.name2,n.name3".format(i) for i in entities]
针对关于问句类型为“食物适用人群”的查询语句模板如下所示:
elif question_type == 'food_eat':
Sql=["MATCH (m:shicia) where m.name='{0}' return m.name,m.yichi".format(i)
for i in entities]
针对关于问句类型为“食物相克”的查询语句模板如下所示:
elif question_type == 'shicai_kezhi':
Sql=["MATCH (m:shiwu)-[r:shicai_xiangke]-(n:xiangke) where m.name = '{0}' return m.name,n.name".format(i) for i in entities]
4.4 答案生成
答案生成部分是将获取到的cypher查询语句放到Neo4j图数据库中运行,然后将查询到的答案存入[‘answer’]数组里,根据[‘question_type’]的类型不同使用对应的答案模板,最后将查询到的结果与答案模板结合起来。如在返回关于疾病宜吃食物的问题答案时,应该返回该疾病的名称、食物名称,实现语句为:
elif question_type == 'disease_food':
Food = [i['n.name'] for i in answers]
Food1 = [i['n.name1'] for i in answers]
Food2 = [i['n.name2'] for i in answers]
Food3 = [i['n.name3'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}患者适合食用:{1},{2},{3},{4}'.format(subject, ';'.join((list(set(Food)))[:self.num_limit]),';'.join((list(set(Food1)))[:self.num_limit]),';