DeepSeek究竟创新了什么?
作者: 马克DeepSeek春节前夕爆火,迄今热度不减。DeepSeek彻底走开源路线,它的大模型既性能优异,训练成本和使用成本又都超低,让人工智能从业者燃起了“我也能行”的希望,让各行各业燃起了“赶紧把人工智能用起来吧”的热情。
伴随着这些振奋人心的消息,也有一些真假难辨的说法同时在流传,例如DeepSeek颠覆了人工智能的发展方向,DeepSeek的水平已超过人工智能行业领头羊OpenAI;或者,DeepSeek是个巨大泡沫,它只是“蒸馏”了OpenAI的模型。
为搞清楚这些说法,这些天我研读了很多资料,也请教了一些专家,对DeepSeek究竟创新了什么、能否持续创新有了初步答案。
先说第一个问题的结论:DeepSeek的大模型采用了更加高效的模型架构方法、训练框架和算法,是巨大的工程创新,但不是从0到1的颠覆式创新。DeepSeek并未改变人工智能行业的发展方向,但大大加快了人工智能的发展速度。
为何会得出这个结论?我们需要先了解人工智能技术的发展脉络。
人工智能简史
人工智能发端于上世纪40年代,已经发展了近80年,奠基人是英国计算机科学家艾伦·图灵(Alan Turing)。以他的名字命名的图灵奖是计算机科学界的诺贝尔奖。
如今,主导人工智能行业的是大模型技术,主导应用是生成式AI——生成语义、语音、图像、视频。无论DeepSeek系列,还是OpenAI的GPT系列,还是豆包、Kimi、通义千问、文心一言,都属于大模型家族。
大模型的理论基础是神经网络,这是一种试图让计算机摹仿人脑来工作的理论,该理论和人工智能同时发端,但头40年都不是主流。20世纪80年代中后期,多层感知机模型和反向传播算法得到完善,神经网络理论才有了用武之地。多人对此作出关键贡献,其中最为我们熟知的是去年获得诺贝尔物理学奖的杰弗里·辛顿(Geoffrey Hinton),他拥有英国和加拿大双重国籍。
神经网络理论后来发展为深度学习理论,关键贡献者除了被誉为“深度学习之父”的杰弗里·辛顿,还有法国人杨·勒昆(Yann LeCun,中文名杨立昆)、德国人尤尔根·施密德胡伯(jürgen schmidhuber)。他们分别提出或完善了三种模型架构方法:深度信念网络(DBN,2006)、卷积神经网络(CNN,1998)、循环神经网络(RNN,1997),让基于多层神经网络的机器深度学习得以实现。
但到此为止,都是小模型时代,DBN和RNN的参数量通常是几万到几百万,CNN参数量最大,也只有几亿。因此只能完成专门任务,比如基于CNN架构的谷歌AlphaGo,打败了顶尖人类围棋手柯洁和李世石,但它除了下围棋啥也不会。
2014年,开发AlphaGo的谷歌DeepMind团队首次提出“注意力机制”。同年底,蒙特利尔大学教授约书亚·本吉奥(Yoshua Bengio)和他的两名博士生发表更详尽的论文。这是神经网络理论的重大进步,极大增强了建模能力、提高了计算效率,让大规模处理复杂任务得以实现。
约书亚·本吉奥、杨·勒昆、杰弗里·辛顿一起获得了2019年的图灵奖。
2017年,谷歌提出完全基于注意力机制的Transformer架构,开启大模型时代。迄今,包括DeepSeek在内的主流大模型都采用该架构。强化学习理论(Reinforcement Learning,RL)、混合专家模型(Mixture of Experts,MOE,又译稀疏模型)也是大模型的关键支撑,相关理论均在上世纪90年代提出,21世纪10年代后期由谷歌率先用于产品开发。
顺便澄清一个普遍误解,MOE并不是和Transformer并列的另一种模型架构方法,而是一种用来优化Transformer架构的方法。

今天的主流大模型,参数量已达万亿级,DeepSeek V3是6710亿。如此大的模型,对算力的需求惊人,而英伟达的GPU芯片正好提供了算力支持,英伟达在AI芯片领域的垄断地位,既让它成为全球市值最高的公司,也让它成为中国AI公司的痛点。
谷歌在大模型时代一路领先,但这几年站在风口上的并不是谷歌,而是2015年才成立的OpenAI,它的各类大模型一直被视为业界顶流,被各路追赶者用来对标。这说明在人工智能领域,看似无可撼动的巨头,其实并非无法挑战。人工智能技术虽然发展了80年,但真正加速也就最近十几年,进入爆发期也就最近两三年,后来者始终有机会。DeepSeek公司2023年7月才成立,它的母体幻方量化成立于2016年2月,也比OpenAI年轻。人工智能就是一个英雄出少年的行业。
开发出能像人一样自主思考、自主学习、自主解决新问题的通用人工智能系统(Artificial General Intelligence,AGI),是AI业界的终极目标,无论奥特曼还是梁文峰,都把这个作为自己的使命。他们都选择了大模型方向,这是业界的主流方向。
沿着大模型方向,要花多久才能实现AGI?乐观的预测是三至五年,保守的预测是五至十年。也就是说,业界认为最迟到2035年,AGI就可实现。
大模型的竞争至关重要,大模型是各行各业人工智能应用的最上游,它就像人的大脑,大脑指挥四肢,大脑的质量决定整个人的学习、工作、生活质量。
当然,大模型并非通往AGI的唯一路径。正如上世纪90年代后“深度学习-大模型”路线颠覆了人工智能头几十年的“规则系统-专家系统”路线,“深度学习-大模型”路线也有可能被颠覆,只是我们现在还看不到谁会是颠覆者。
DeepSeek创新了什么?
如今,DeepSeek又成了挑战者,它真的已经超越OpenAI了吗?并非如此。DeepSeek在局部超过了OpenAI的水平,但整体而言OpenAI仍然领先。
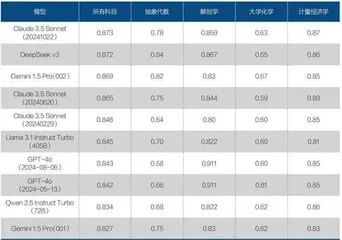
先来看双方的基础大模型,OpenAI是2024年5月发布的GPT4-o,DeepSeek是2024年12月26日发布的V3。斯坦福大学基础模型研究中心有个全球大模型综合排名,最新排名是今年1月10日,一共六个指标,各指标得分加总后,DeepSeek V3总分4.835,名列第一;GPT4-o(5月版)总分4.567,仅列第六。第二到第五名都是美国模型,第二名是Claude 3.5 Sonnet,总分4.819,开发这个模型的Anthropic公司2021年2月才成立。
推理模型是大模型的新发展方向,因为它的思维模式更像人,前面说了,开发出能像人一样自主思考、自主学习、自主解决新问题的通用人工智能是AI业界的终极目标。
2024年9月12日,OpenAI发布世界上第一款推理大模型猎户座1号(orion1,o1),o1在解决数学、编程和科学问题上的能力提升惊人,但OpenAI走闭源路线,不公布技术原理,更别提技术细节。一时间,如何复刻o1,成为全世界AI从业者的追求。
仅仅四个月后,今年1月20日,DeepSeek发布世界第二款推理大模型R1,名字朴实无华,R就是推理(Reasoning)的缩写。测评结果显示,DeepSeek-R1与OpenAI-o1水平相当。但OpenAI 2024年12月20日推出了升级版o3,性能大大超过o1。目前还没有R1和o3的直接测评对比数据。
多模态也是大模型的重要发展方向——既能生成语义(写代码也属于语义),也能生成语音、图像、视频,其中视频生成最难,消耗的计算资源最多。DeepSeek2024年10月发布首个多模态模型Janus,今年1月28日发布其升级版Janus-Pro-7B,其图像生成能力在测试中表现优异,但视频能力如何尚无从知晓。GPT-4是多模态模型但不能生成视频,不过OpenAI拥有专门的视频生成模型Sora。
把模型做小做精,少消耗计算资源是另一个业界趋势,混合专家模型的设计思路就是这个目的,推理模型也能减少通用大模型的惊人消耗。在这方面,DeepSeek的表现明显比OpenAI优异,这些天最被人津津乐道的就是DeepSeek的模型训练成本只有OpenAI的1/10,使用成本只有1/30。DeepSeek能够做到如此高的性价比,是因为它的模型里面有杰出的工程创新,不是单点创新,而是密集创新,每一个环节都有杰出创新。这里仅举三例。
斯坦福大学基础模型研究中心全球大模型综合性能排名
★模型架构环节:大为优化的Transformer + MOE组合架构。
前面说过,这两个技术都是谷歌率先提出并采用的,但DeepSeek用它们设计自己的模型时做了巨大优化,并且首次在模型中引入多头潜在注意力机制(Multi-head Latent Attention,MLA),从而大大降低了算力和存储资源的消耗。
★模型训练环节:FP8混合精度训练框架。
传统上,大模型训练使用32位浮点数(FP32)格式来做计算和存储,这能保证精度,但计算速度慢、存储空间占用大。如何在计算成本和计算精度之间求得平衡,一直是业界难题。2022年,英伟达、Arm和英特尔一起,最早提出8位浮点数格式(FP8),但因为美国公司不缺算力,该技术浅尝辄止。DeepSeek则构建了FP8混合精度训练框架,根据不同的计算任务和数据特点,动态选择FP8或FP32精度来进行计算,把训练速度提高了50%,内存占用降低了40%。
★算法环节:新的强化学习算法GRPO。
强化学习的目的是让计算机在没有明确人类编程指令的情况下自主学习、自主完成任务,是通往通用人工智能的重要方法。强化学习起初由谷歌引领,训练AlphaGo时就使用了强化学习算法,但是OpenAI后来居上,2015年和2017年接连推出两种新算法TRPO(Trust Region Policy Optimization,信任区域策略优化)和PPO(Proximal Policy Optimization,近端策略优化),DeepSeek更上层楼,推出新的强化学习算法GRPO(Group Relative Policy Optimization组相对策略优化),在显著降低计算成本的同时,还提高了模型的训练效率。
看到这里,对于“DeepSeek只是‘蒸馏’了OpenAI模型”的说法,你肯定已经有了自己的判断。但是,DeepSeek的创新是从0到1的颠覆式创新吗?
显然不是。颠覆式创新是指那种开辟了全新赛道,或导致既有赛道彻底转向的创新。比如,汽车的发明颠覆了交通行业,导致马车行业消失;智能手机取代功能手机,虽没有让手机行业消失,但彻底改变了手机的发展方向。