基于UNET模型的图像去噪算法优化研究
作者: 马文曦 杨蕾 肖娟
摘要:文中运用了卷积神经网络结合照亮每一处黑暗(Lighting Every Darkness,LED) 策略处理图像去噪,基于U-Net模型引入了重新参数化噪声去除模块(Reparameterized Noise Removal,RepNR) ,以提升去噪及泛化能力。经过虚拟相机采样合成噪声图像预训练与目标相机少量图像微调后,系统可快速部署于特定相机中。经仿真试验验证,对极低光照条件下的索尼A7S2图像集进行图像去噪任务(Extreme Low-light Denoising,ELD) 处理后,结果显示本文算法的去噪效果优于ELD算法,图像灰度更集中、频谱高频成分更少、等高线更平滑,且在特定条件下训练时间最短。
关键词:图像去噪;U-Net模型;噪声建模;深度学习
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2025)07-0001-05
开放科学(资源服务) 标识码(OSID)
0 引言
基于学习的图像去噪方法虽在使用成对真实数据集时取得进展[1],但为各相机型号定制广泛的真实原始图像格式(Raw Image Format,RAW) 图像数据集不切实际,因其获取成本高。这促使人们使用合成数据集,但用合成数据训练的去噪方法处理真实照片性能差,急需找到缩小二者差距的途径。探索合成数据集与真实图像去噪的结合,有助于深入理解噪声特性和去噪算法。通过研究可把握其物理规律与统计特性,为算法设计提供坚实理论基础,为图像去噪算法的发展带来新方向和思路,推动算法不断进步。
在消除合成图像与真实照片领域差距方面,Linh Duy Tran等人[2]提出使用生成对抗网络(Generative Adversarial Network,GAN) 来模拟真实噪声模式;Yoonsik Kim等人[3]通过迁移学习将大规模合成图像数据集上训练好的模型迁移到真实图像数据集上进行微调。在基于校准的噪声合成方法方面,Kaixuan Wei等人[4]通过深入研究光照条件、传感器特性等物理因素构建精确噪声模型,提高了算法对真实噪声的处理能力。Jin X等人[5]摒弃了传统基于显式校准的噪声模型,通过虚拟相机预训练和目标相机少量样本微调的两阶段方法,显著提升了算法在不同相机模型上的适应性和去噪效率。Feng H等人[6]从数据视角出发,利用噪声建模来改造真实配对数据,使其能够提供可学习性更好的数据映射供神经网络学习,提升去噪效果。
本文采用了卷积神经网络,首先使用了LED策略[5]对图像去噪过程进行了处理,在预训练时采用LED策略,选用五个虚拟相机进行训练,而在微调部署阶段,以新视角看待数据映射关系,降低噪声复杂度。其次,通过将LED与用于降噪的成对数据建模(Pairwise Data Modeling for Noise Reduction,PMN) 的训练策略[6]相结合,降低了部署阶段的实验时间。同时,改变部署阶段迭代次数后,在使用PMN训练策略时,即使迭代次数很大也不影响模型学习数据特征。这不仅为图像去噪算法的发展提供了新的思路和方法,还切实解决了部署阶段实验时间长以及迭代次数对模型学习数据特征影响的问题。
1 算法设计原理
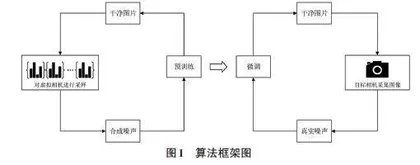
文中所提核心算法是基于U型网络架构(U-Net: Convolutional Networks for Biomedical Image Segmentation,U-Net) 模型的图像去噪方法,该算法框架如图1所示。
整个算法流程分为4个关键阶段:1) 对一组m台虚拟摄像机进行采样,后期负责合成噪声;2) 利用m个相机特定对齐参数(Camera-Specific Alignment,CSA) 合成配对图像,并对去噪网络进行预训练;3) 利用目标相机获取有限数量的真实噪声图像对;4) 利用真实噪声数据对预训练的去噪网络进行微调,使网络适应目标摄像机的特点。
1.1 噪声模块设计原理
所提算法中的传感器模型采用的是目前占主导地位的互补金属氧化物半导体(Complementary Metal-Oxide-Semiconductor,CMOS) 传感器模型。该模型模拟了入射光从光子转换为电子,再从电子转换为电压,最后从电压转换为数字的噪声电子成像管道[7]。CMOS传感器简化成像模型如图2所示。
在原始图像空间中,通常将捕获的信号D视为干净图像I与各种噪声分量N的和,表示为[Eqn]:
[D=I+N] (1)
式中:D为捕获的信号,I为干净图像,N为噪声分量。
假设N遵循噪声模型:
[N=Ndark+Nread+Nrow+Nquant+ε] (2)
式中:[Ndark]、[Nread]、[Nrow]、[Nquant]和[ε]分别代表暗电流噪声、读取噪声、行噪声、量化噪声和模型外噪声。
除模型外噪声外,其他噪声分量从特定分布中采样:
[Ndark+I~P1KK] (3)
[Nread~Tλ;μc,σT] (4)
[Nrow~N0,σT] (5)
[Nquant~U-12,12] (6)
式中:K为系统总体增益,P、N和U分别代表泊松分布、高斯分布和均匀分布。[Tλ;μc,σT]为Tukey-lambda分布,形状为[λ],均值为[μ],标准差为[σ]。
根据ELD中的假设[4],[K,σT]和[K,σr]的联合分布服从线性关系,表示为:
[logK~UlogKmin,logKmax] (7)
[logσTlogK~NaTlogK+bT,σT] (8)
[logσrlogK~NarlogK+br,σr] (9)
式中:[Kmin]、[Kmax]表示整个系统增益的范围,由最小和最大感光度(International Standards Organization,简称ISO值) 决定。a、b和[σ]分别表示线的斜率、偏置和标准差的无偏估计量。
在这种情况下,相机可以近似为一个十维坐标C:
[C=Kmin,Kmax,λ,μc,aT,bT,σT,ar,br,σr] (10)
所提算法中的数据构成的参数空间进行采样后得到坐标C,如公式(10) 所示。
1.2 训练策略
可学习性增强框架如图3所示。本算法的训练策略包含散点噪声增强(Shot Noise Augmentation,SNA) 和暗阴影校正(Dark Shading Correction,DSC) 两种有效技术。SNA通过增加数据量提高数据映射精度,而DSC通过降低噪声复杂度来降低数据映射的复杂度。
SNA是针对散粒噪声的数据增强方法,通过增加散粒噪声不断合成新的无噪声数据对,以增加有限的数据量。DSC是对读噪声的解耦,先校准时间稳定分量(暗阴影) ,再在校正后的成对真实数据中降低噪声复杂度。SNA和DSC都不改变噪声模型,可在不破坏真实噪声分布的情况下增强映射的可学习性。
训练时,先用DSC校正噪声原始图像中的暗阴影,再通过SNA对干净图像和噪声图像进行增强,得到新的数据对。最后,用增强的噪声图像和增强的干净图像训练具有U-Net结构的去噪器。推理时,使用训练好的去噪模型对暗阴影校正后的噪声图像进行去噪。
1.3 基于U-Net模型的图像去噪
U-Net网络架构图如图4所示,从其架构图上可以明显看出其两大特点:第一,U-Net网络呈现出对称的“编码器-解码器”架构;第二,在编码器和解码器之间,存在着直接相连的跳跃连接。
正是因为其架构上的显著特点,U-Net网络模型可以同时捕捉图像的全局信息(通过编码器) 和局部细节信息(通过解码器) ,并且解码器可以获取到编码器中丰富的低级特征信息,这有助于在恢复图像细节时保留更多的原始信息,避免在处理过程中丢失重要的图像细节。U-Net的架构相对简洁,在保证性能的同时,计算效率较高。与一些更为复杂的网络架构相比,U-Net的参数数量相对较少,计算复杂度较低,这使得它在训练和推理过程中都能够更快地运行。这也是本文算法选择U-Net网络模型作为改进基础的原因。
基于U-Net模型的图像去噪算法,首先构造了U-Net网络架构,并在其架构上引入了重新参数化噪声去除模块(RepNR) 。在U-Net网络架构中,RepNR模块取代了原有的卷积块,成为新的核心处理单元,这样的操作不会产生额外的成本[8],也有利于后续与其他方法进行比较。该模块在预训练阶段和微调阶段采用了不同的优化策略。
针对不同阶段对RepNR块引入了不同的优化策略。为了处理真实噪声,用一个新的相机特定对齐(Camera-Specific Alignment,CSA) 层代替多分支CSA层,表示为CSAT。与预训练期间的多分支CSA不同,CSAT层通过平均预训练的CSA来初始化,以提高泛化能力。CSAT之后的3×3卷积分支即为模型内噪声去除分支(In-Model Noise Removal,IMNR) 。
CSA层是专门为对齐由合成噪声增强的特征而设计的,但在真实噪声和IMNR可以处理的噪声(即公式中的ε) 之间仍然存在差距。因此,引入模型外噪声去除分支(Out-of-Model Noise Removal,OMNR) ,以衡量真实噪声与建模分量之间的差距。
OMNR仅包含一个3×3卷积,旨在从少量原始图像对中捕获真实噪声的结构特征。鉴于缺乏噪声余项的先验信息,将OMNR的权重和偏置初始化为张量0。将IMNR与OMNR结合可得到RepNR块。
CSAT的初始化策略和再参数化过程说明如图5所示。其中图5(a)为预训练期间的RepNR模块;图5(b)为参数共享块,将RepNR块看作是m个参数共享块,每个块对应一个特定的虚拟摄像机;图5(c)为CSAT生成,通过平均预训练的CSA来初始化CSAT,这可以被认为是模型集成;图5(d)为再参数化过程,将部署期间的参数重新更新,代表重新参数化。
CSAT初始化分析如上所述,通过在多分支CSA层中平均预训练的CSA来初始化CSAT。考虑到在多分支CSA中,每条路径都共享卷积,这个初始化可以被定义为m个模型的集合,其中m为路径的个数,如图5中的(a)~(c)所示。
与其他同类型的去噪网络类似[9],本算法使用了L1损失。对于图像去噪任务,L1损失(平均绝对误差,MAE) 能够有效地衡量去噪后图像与原始干净图像之间的差异。它关注的是像素值的绝对差异,这与人类视觉系统对图像质量的感知有一定的相关性。
L1损失的优点在于它对异常值相对不那么敏感,相比于其他一些损失函数,在处理数据中的离群点时能更稳健地反映模型预测与真实值之间的偏差。计算方式简单直观,就是预测值与真实值之差的绝对值的平均值,易于理解和实现。
2 仿真试验
2.1 试验参数
试验数据分别来自SID(See in the Dark) 项目[10]与ELD项目的公开数据。SID数据集中分别有大小为12GB的Sony A7S2清晰-噪声图像对与22GB富士清晰-噪声图像对,ELD的公开数据集中含有Canon EOS 70D、Canon EOS 700D、Nikon D850、Sony A7S2四款相机的图像。
在训练时,采用SID的索尼数据集的子集进行训练,随机选择每个额外数字增益(×100、×250和×300) 下的两对数据,共6对作为少样本训练数据集。测试时则使用ELD数据集中的数据进行测试,使用前两个场景的配对原始图像对预训练网络进行微调,剩余八个场景用于评估,即微调集与测试集的比例约为1∶4。将使用的所有数据全部转化为与SID数据集同样的格式后进行裁剪,裁剪成长度和宽度均为512像素、步长为256像素的非重叠图像块,通过这种方式增加了每个epoch的迭代次数(从161次增加到1 288次) 。本文算法各阶段的详细迭代次数与学习率如表1所示。