基于改进YOLOv8的大米袋包装表面缺陷检测
作者: 孟剑扬 李欢欢 欧阳虹 赫明茹 王安
摘要:为解决传统米袋包装表面缺陷检测方法效率和精度欠佳的问题,文章提出一种基于YOLOv8n的改进模型。该模型通过引入Wise-IoU损失函数和GAM注意力机制,提升了边界框回归速度和目标定位精度。在自建RICE_PACKAGE-DET数据集上的实验结果表明,改进模型的[email protected]和[email protected]相比基准模型分别提升2.4%和2%,平均检测精度达到96.8%。
关键词:YOLOv8算法;缺陷检测;注意力机制;深度学习;Wise-IoU
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2025)07-0029-05
开放科学(资源服务) 标识码(OSID)
0 引言
大米袋包装的完整性直接影响大米质量和市场价值。然而,传统的缺陷检测方法存在效率低、漏检率高等问题,因此亟须开发自动化、高精度的检测方法。
为了解决上述问题,本文提出了一种基于改进YOLOv8的缺陷检测方法,本文主要进行了如下工作。
1) 通过采用多种数据增强手段模拟实际情形,构建了一个专门针对制造组装后的大米袋包装的数据集RICEPACKAGE-DET。
2) 提出了一种基于YOLOv8n的小目标检测模型。改进的模型在YOLOv8n的基础上在骨干网络中使用了GAM_Attention注意力机制,在损失函数的优化环节中,融入了动态非单调的聚焦机制,运用Wise-IoU损失函数来构建模型结构。
3) 针对所构建的模型,在RICE_PACKAGE-DET数据集上开展了大量的实验。实验所获取的数据有力地证实,文中所提出的经过改进的这一模型,在大米包装缺陷检测方面展现出了十分理想的精度水平,能够较好地满足实际检测需求。
1 相关领域研究
近年来,基于深度学习的计算机视觉算法在大米袋包装表面缺陷检测领域取得了显著进展,为实现自动化、高效的检测流程以及实时监控提供了可靠技术支持[1]。
目标检测方法从深度学习的角度划分,主要分为两类:基于锚框(Anchor-based) 和无锚框(Anchor-free) 。Anchor-based方法,如Faster R-CNN等,通过预设一系列不同尺度和长宽比的锚框(Anchor) 生成候选区域,从而进行目标检测。在包装缺陷检测中,这类方法能够利用锚框对不同大小和形状的缺陷进行初步定位,在一些规则包装且缺陷特征较为明显的场景下,能取得不错的检测效果。然而,其局限性在于锚框的设计需要人工经验,且计算量较大,对小目标和形状不规则的缺陷检测效果欠佳,容易出现漏检情况。
Anchor-free方法,像CornerNet、CenterNet等,则摒弃了锚框,直接预测目标的关键点或中心位置等。在包装缺陷检测应用中,它们能够更灵活地检测目标,减少对锚框的依赖,在检测小目标缺陷时具有一定优势。不过,这类方法对于复杂背景下的缺陷检测,由于缺乏有效的背景过滤机制,容易受到背景噪声干扰,导致误检率升高。
YOLOv8作为一种先进的目标检测模型,网络结构包含主干网络(Backbone) 、颈部网络(Neck) 以及检测头(Head) [2]。针对包装缺陷检测问题,Sheng等采用 ECA-EfficientDet 算法,通过 mosaic 数据增强、设计 ECA-Convblock、引入 Mish 激活函数和异构数据迁移学习,在小样本下实现了 99.16% 的高精度检测[3]。Vua等构建基于 YOLO 算法的实时检测系统,通过实时视频接收、缺陷检测和自动分类等模块实现对包装缺陷的检测,虽存在一些局限,但为实际应用提供了思路[4]。Shuai等针对金属齿轮端面缺陷检测难题,提出 SF-YOLO 方法,利用显著区域提取、BiFPN模块和改进的麻雀算法优化,有效提高了检测精度和效率,满足企业实时检测需求[5]。赵敏等针对包装盒缺陷检测精度低和泛化能力差的问题,将 YOLOv5s 主干网络替换为Swin-Transformer并加入正则化方法,使mAP提升0.7%,提高了模型检测性能[6]。
尽管以上方法取得了一定进展,但在实际应用中仍存在不足。在检测大米袋包装上的微小针孔缺陷这类小目标时,一些基于 Anchor-based 的方法由于锚框尺度设置问题,难以准确捕捉到小目标,导致漏检情况频发。而对于复杂背景下的缺陷检测,如大米袋上有多种图案和文字的情况下,Anchor-free 方法容易将背景中的图案误判为缺陷,导致误检率升高。在面对遮挡目标时,现有方法往往难以准确识别被部分遮挡的缺陷,使得检测精度大幅下降,无法充分满足大米袋包装缺陷检测的实际需求 。
2 YOLOv8 目标检测模型
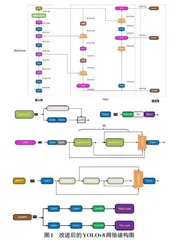
YOLOv8 作为前沿的目标检测模型,其网络架构主要由主干网络(Backbone) 、颈部网络(Neck) 和检测头(Head) 构成。
待检测图像输入后,Backbone负责提取特征。它通过卷积与反卷积层,结合残差连接和瓶颈结构,缩小网络规模并提升特征提取性能。其中,C2f模块作为基础单元,相比YOLOv5的C3模块,因引入分割操作和更多跨层连接,获取了更丰富梯度流,以更少参数量实现更优的特征提取。
Neck在三个尺度上融合Backbone提取的特征,提高对不同尺寸目标的检测效果。其包含SPPF、FPN和PAN,SPPF把不同尺寸特征图转为固定特征向量,FPN自上而下传递语义信息,PAN自下而上传递定位信息,三者协同实现多尺度特征融合。
Head采用解耦检测头设计,摒弃基于锚框的预测,改用无锚框方法。通过分类和回归两个独立分支,检测头经卷积与反卷积层生成检测结果,分类头用全局平均池化对特征图分类,最终实现目标的精准分类与定位。改进后的网络结构图如图1所示。
3 优化方案
3.1 损失函数优化
YOLOv8原回归损失计算采用DFL和CIoU的结合。在面对复杂多样的缺陷样本时,难以有效平衡不同质量样本的学习,无法有效区分不同质量的锚框,导致对部分缺陷的定位和识别不够准确,增加计算复杂性,影响整体检测性能。传统的CIoU的表达式如下。
[[LCIoU=1-IoU+ρ2(b,bgt)c2+αv.] (1) [v=4π2(arctanwgthgt-arctanwh)2.] (2) [α=v(1-IoU)+v] (3) ]
式中,参数解释如下,IoU是预测框与真实框的交集面积与并集面积的比值,b表示预测框的中心点坐标,[bgt]表示真实框的中心点坐标, [ρ2(b,bgt)]是两个中心点之间的欧氏距离的平方,是能够同时包含预测框和真实框的最小闭包区域的对角线长度,[wgt]和[hgt]分别表示真实框的宽度和高度,[v]用于衡量宽高比的一致性。[α]是一个平衡因子,它根据[v]和[IoU]的值来动态调整在损失函数中的权重,用于调整宽高比的一致性。
在大米袋包装缺陷检测场景中,存在破洞、污渍、封口不严等多种缺陷且样本质量不一。如微小破洞因与背景对比度低成为低质量样本,原损失函数因侧重高质量样本,易忽略此类样本,致使缺陷定位不准,降低整体检测精度。本文引入Wise-IoU来代替CIoU作为YOLOv8算法的回归损失。
Wise-IoU[7]模型在平衡样本方面通过“离群度”计算聚焦系数,用于评估锚框质量。Wise-IoU能根据锚框质量对高低质量锚框分别降低其梯度增益,而 CIoU 没有这种根据锚框质量动态调整的机制。在处理低质量样本时,Wise-IoU通过这个公式能平衡不同质量样本在训练中的作用,克服了CIoU处理低质量样本的不足。FM 机制依据“离群度”动态分配梯度增益,通过灵活调整学习重点,使得模型在训练时能更关注需要学习的锚框,改善了 CIoU梯度分配不合理的问题 。
[[LWIoUv3=rLWIoUv1,r=βδαβ-δ] (4) ]
[LWIoUv1] 是 Wise - IoU v1版本的损失函数值,[LWIoUv3]是Wise - IoU v3版本的损失函数值。[β]用于衡量锚框的质量或其与理想状态的偏离程度。[r]为聚焦系数,[α]和[δ]均为超参数。
3.2 GAM注意力机制
在深度学习领域,注意力机制是一类能够有效提升模型性能的重要技术,注意力机制通常涵盖通道注意力、空间注意力以及通道空间注意力。将其引入模型中,能够强化模型对目标特征表征的学习,让模型对目标的理解和识别能力得到进一步提高。
由于米袋包装表面缺陷呈现出多样性和复杂性的特点,致使模型在检测时,可能难以识别出某些缺陷,或者检测结果的准确性欠佳。在这种情况下,注意力机制的优势得以凸显,能够有效改善上述问题 。
本文将 GAM[8]注意力机制融入骨干网络以提升大米包装袋缺陷检测性能。常见的 CBAM、CA 等注意力机制在处理通道和空间信息交互时有局限,而 GAM 能有效解决。在大米包装袋缺陷检测中,GAM 可精准捕捉缺陷特征,提高检测准确性与效率,显著增强了模型表征能力,为保障包装质量提供有力支持。
GAM 注意力模块的结构如图2所示,其主要作用是对图像特征进行处理。具体来说,给定输入特征图 F1、中间状态特征图 F2 和输出特征图 F3 。首先,将F1 与通道注意力图 Mc 进行逐通道相乘,凸显重要通道特征。然后,空间注意力图 Ms 再和得到的特征进行逐元素乘法运算,此模块通过这样的方式实现对图像特征重要信息的提取,同时强化不同通道与空间之间的交互,其本质是一种基于全局观察和建模的机制,具体计算公式如下:
[[F2=MC(F1)⊗F1=sigmoid[K1⋅ReLU(w2y+b2)T]] (5) [y=w1KT1+b1] (6) [F3=MS(F2)⊗F2=sigmoid[ConvBN(ConvBNReLU(K2))]] (7) ]
通道注意力子模块如图3所示,该模块在三个维度上运用3D置换策略,保留关键信息。通过双层多层感知机(MLP) 增强通道与空间的关联,以此提升对特征信息的处理能力与效率,为后续任务提供更具判别力的特征表示。
如图4所示的是空间注意力子模块,通过两个7×7大小的Conv卷积操作,对输入图像的空间信息进行融合。为了确保与通道注意力子模块在参数设置上的协调性,二者采用相同的缩小比率,以此实现两个模块在整体架构中的协同运作,进一步提升模型处理空间特征的效果和效率。
4 结构分析
4.1 实验环境
采用 YOLOv8 原始的 NMS来从候选框中选出最相关的目标检测框[9]。训练阶段,摒弃所有预训练权重,直接以自建的 RICE_PACKAGE-DET 数据集展开训练。训练设定最终学习率为 0.000 1,权值衰减系数为 0.000 5 ,以此优化模型训练效果。实验环境如表1所示。
4.2 RICE_PACKAGE-DET 数据集获取
在米袋包装运输时,米袋容易受到损伤。本文聚焦这一问题,以锐角裂、矩裂隙、圆扩痕和锯齿状裂痕作为典型缺陷,构建专属数据集。利用大恒相机,在不同光照与角度条件下,拍摄存在各类缺陷的米袋包装。图像采集平台的整体结构涵盖工业相机、镜头、光源、传送带以及非标视觉检测支架。
RICE_PACKAGE-DET 数据集,专用于米袋包装缺陷检测,含3 216个经数据增强的图像及对应YOLO标签。本研究按3∶1∶1随机分其为训练、验证、测试集来实验。
4.2.1 数据处理与增强
在深度学习领域,模型训练往往需要大量图像。为了满足这一需求,对图像展开了一系列预处理工作[10]。原始图像的尺寸为640×640 px,研究者首先对其进行了自上而下、从左到右的切片操作。然而,切片完成后,发现存在数据集规模较小和缺陷类别分布不均衡的问题。为了解决这些问题,引入数据增强策略显得尤为必要。数据增强不仅能够扩充数量较少的缺陷类别所对应的图像,有效改善数据的不平衡状况,还能在一定程度上提升模型的性能,增强模型的泛化能力,防止模型在训练过程中出现过拟合现象,从而让模型在实际应用中表现得更加稳健和准确。本实验采用的数据增强方法如下:1) 几何变换增强:缩放、翻转、旋转;2) 颜色和亮度调整;3) 噪声添加:椒盐噪声、高斯噪声;4) 模糊处理增强:模糊、平移。