基于数据挖掘技术对颈动脉硬化斑块的诊断研究
作者: 董雪 杨婉琦
摘要:近年来,我国中老年人群中患有颈动脉硬化的人占比逐渐增多,低龄化趋势也越来越明显,该疾病已成为导致中老年人死亡率上升的头号危险因素。超声检测作为颈动脉硬化诊断的常用手段,可为诊断提供血流动力学参数、回声特征、斑块厚度、长度等数据,这重要数据不断累积于医院电子病历数据库中,而对它们的处理大多仍采用人工方式。因此,数据挖掘技术在辅助医生进行临床诊断方面具有重要潜力。
关键词:颈动脉硬化斑块;数据挖掘;XGBoost 算法;BP 神经网络
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2025)07-0071-03
开放科学(资源服务) 标识码(OSID)
0 引言
随着我国经济水平的提高,人们的生活方式和饮食习惯发生了显著变化,导致颈动脉硬化等疾病的发病率不断上升,且呈现出年轻化趋势[1]。颈动脉硬化是导致中老年人死亡率升高的头号危险因素,严重威胁着人们的正常生活与工作,对该疾病相关数据的处理有助于提升诊断效率,挖掘相关致病因素,为病人提供更加科学的诊断方案。然而,目前大多数医院对医疗数据的处理仍停留在简单的增删改查和人工分析阶段,缺乏对数据的深度挖掘和利用。大量高维数据的处理仅依靠人工分析不仅效率低下,而且容易出现误差,难以满足临床诊断的需求。数据挖掘技术可以有效地识别数据中的潜在模式和关联信息,为医生提供更准确、客观的诊断依据,辅助临床决策。
1 颈动脉硬化临床检测
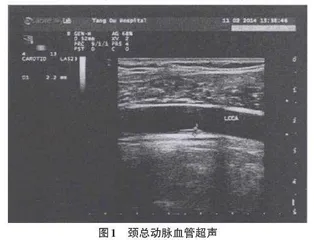
颈动脉硬化是临床常见疾病,严重危害中老年人的健康。目前,临床上常用的颈动脉硬化检测方法包括螺旋CT血管造影、超声血管检查和磁共振血管造影等。其中,超声检查从20世纪50年代就已经产生,通过对超声波的物理特性分析与研究和超声波成像原理的运用结合人体器官的生物学特征与病理特征,来观测超声信息在人体的器官形态和功能方面的表现,以此来对某种疾病进行诊断分析。而超声作为一种具有无创性、实时、简便以及检查费用低廉等优点成为目前颈动脉硬化诊断中应用最广泛的手段之一,超声血管检查的方式可以将体表大动脉清楚地显示出来,特别是对于颈动脉血管壁的各种状况的显示[2],但受环境等因素的影响,超声检测所得数据也存在一定的错误与冗余。如图1所示,就是利用超声血管检查的方式展示出来某患者颈总动脉血管内的情况。
一个完整的颈动脉超声检查不仅是对颈总动脉的检查,还对颈内、颈外以及椎动脉进行相应的检查。通过超声检查可对颈动脉所处位置、具体形状、内中膜厚度、呈现的大小以及血流的动力学变化等情况做出检测,其中血流动力学信息对颈动脉硬化斑块的诊断有着重要作用,图2所示为某颈动脉硬化患者的血流信号频谱图。
颈动脉狭窄现象的出现是因为有斑块的形成,而颈动脉血流动力学信息也是随着狭窄程度的不同而呈现不同的变化。临床上,当颈动脉血管正常时,多普勒超声信号频谱中所显示的血流信息参数,收缩期峰值流速通常在60~100 cm/s范围内,舒张期末期流速小于40 cm/s。当颈动脉血管有异常现象出现时,就是导致颈动脉内径变小,包括颈内动脉以及椎动脉,血管内部变得迂回弯曲,血流过程中的阻力变大,血流量与正常血管相比有所减少,致使收缩期峰值流速、阻力指数、搏动指数升高。国际上,颈动脉狭窄通过2003年放射年会超声会议上发表的准则来进行判断,如表1所示。
由上文中关于舒张末期值Vmin点及收缩期的峰值流速Vmax点的定义可得到的是,Vmin和Vmax分别代表着最大频率曲线上的最小值及最大值。同时,对于颈动脉的内径可由多普勒超声血流信号频谱来提供,单位可记作mm;TAMAX来表示平均血流速度,其值可定义为在一个周期内血流速度的积分与心动周期的时间之比,单位同样记作cm/s;血流量记为CBF,单位是ml/min,指的是血管横截面积在一个运动周期内随时间的变化;Vmax/Vmin即收缩期峰值流速与舒张末期值的比值,能够体现血管阻力状况的一项指标即阻力指数RI与血管顺应性与弹性状态的指标搏动指数PI。这些参数在一定程度上反映了颈动脉血流状况和狭窄程度,同时在对颈动脉硬化斑块疾病的诊断中也具有非常重要的含义[3]。
2 数据挖掘技术应用
2.1 数据挖掘流程
数据挖掘属于一种适应性综合方法,可代表待选模型的反复产生过程,其中待选模型的复杂度处于逐渐增加的状态。该方法的核心技术为GMDH,通过GMDH技术只需要完成初始输入函数以及传递函数等的指定,即可从观测样本中自动生成数据模型。为实现数据的深度挖掘,数据挖掘方法应满足3个核心条件。
1) 应包含一个简单的初始组织。
2) 可使组织产生突变的机制(该机制主要在训练数据集的基础上提出假设) 。
3) 该方法内部应包含一个选择机制,将组织改善作为目标进行突变的评价。
通过数据挖掘实现模型建立时,首先应将样本数据划分为训练集以及检测集,其中训练集中存在的颈动脉血流数据主要用于模型建立中,包括参数估计数据以及结构综合数据等:检测集中包含的数据仅在选择最优复杂度模型时被使用,在模型建立过程中不被使用。数据挖掘算法实际上是一种对数据进行分组处理的方法,由数据挖掘算法中的样本数据可完成各项数据挖掘技术的本质区分,数据挖掘算法整体流程如图3所示[4]。
数据挖掘算法整体流程主要在领域理论的基础上进行实现,其运作流程为:首先利用先验信息对数据挖掘模型知识提取能力进行整体提升,知识的提取主要通过数据和科学理论结合的方法实现。该方法在一定程度上对领域理论具有完善作用,将其应用于颈动脉硬化斑块的诊断中,可向医生提供获取知识的方法或者新的理论范畴,有利于帮助医生做出更加科学的诊断决策。
2.2 颈动脉数据预处理
历史数据的数量及质量可直接决定颈动脉硬化斑块诊断模型的性能。传统提取信息的方法,发生数据异常以及数据缺失等情况的概率极高,易受到外界因素以及人为等因素的影响,从而产生低精度或者失效的测量数据,若将该数据直接应用于诊断系统中,可造成系统整体性能的大幅度下降,最终无法保证预测的准确性。并且颈动脉硬化斑块预测模型建立过程中,系统内部各输入变量之间相互影响程度较大。为保证系统对颈动脉硬化斑块诊断精准性,应对数据进行预处理。
2.2.1 数据规范化处理
由于超声检测过程中产生的测量数据存在量纲不同的问题,若量纲不同可直接造成测量数值的差异性,从而引发数据范围的不确定性。数据差异性的扩大可直接影响颈动脉硬化斑块诊断模型的精准性,使该模型的精度无法满足临床要求。为提升预测模型的预测精度,数据的范围会被规范化。规范化方法是建立最小值与最大值之间的关联,将颈动脉血流数据中大小、单位不相同的数据统一到一定范围内,如公式(1) 所示[5]。
[χ'=χ-AminAmax-Amin×Lmax-Lmin+Lmin] (1)
在公式(1) 中,随机颈动脉硬化患者的身体数据记作[χ],重新规划后的值使用[χ']进行表示。[Amax,Amin]分别代表源数据集中的最大值与最小值,二次规划数据集中的最大值与最小值用[Lmax]和[Lmin]表示。
2.2.2 数据相关性分析
数据相关性分析是衡量两个或多个变量之间关系强度和方向的重要统计方法,有助于理解变量间的相互影响。数据挖掘时采用的颈动脉硬化样本数据库中存在较多变量,为保证系统可从大规模的数据集中挖掘出各变量之间的关联,采用降维的方法进行样本数据的确定。降维方法实际上是对各变量进行预测,利用变量之间的相关结构实现预测变量个数的减少。该方法主要有因子分析法,该方法为描述各变量之间的相关性,对变量相关系数的结构进行分析,以此找到可以反映全部变量中少数个变量。通常情况下少数变量属于不可预测的变量,可将其称之为因子。在相关性分析的基础上,按照数据相关性的大小对变量进行分组,有利于提高组内变量的相关性,并降低不同组内变量的相关性[6]。因子分析法的主要步骤如图4所示。
2.3 常用数据挖掘算法
数据挖掘算法的选择是数据挖掘流程中至关重要的一步,它们用于从大量数据中提取有价值的信息和模式。在众多数据挖掘算法中,XGBoost和BP神经网络在机器学习和大规模数据处理领域的突出表现而受到广泛关注。XGBoost在处理大规模数据集时具有更快的训练速度和更高的效率,通过集成多个决策树来提高预测准确性,而BP神经网络具有容错性高且强大的非线性映射能力,适用于解决复杂的预测和分类问题。颈动脉硬化数据具有非线性、规模大且诊断模型需要有准确的预测能力,且一定的容错性等特点,因此这两种算法适用于解决这类问题。
2.3.1 XGBoost
XGBoost是集成学习的一种实现,通过组合多个模型的预测结果,来减少模型的偏差和方差,从而提高模型的泛化能,以获得更准确的预测[7]。XGBoost是一种高效、灵活且可扩展的梯度提升决策树算法。高效性体现在它采用了高效的列块存储结构和高效的并行计算策略,使得训练速度比其他梯度提升算法快很多。灵活性表现为它支持自定义的损失函数和评估指标,这使得它能够灵活地应用于各种回归、分类和排序任务。可扩展性体现为可以在分布式计算环境中进行训练,支持在多台机器上处理大规模数据集。XGBoost在数据挖掘领域的实际应用中有着不俗的表现。XGBoost的工作原理可以概括为以下步骤。
1) 初始化模型:XGBoost首先构建一个简单的初始模型,通常为单个决策树。
2) 迭代构建弱学习器:XGBoost使用梯度提升方法迭代地构建决策树。在每轮迭代中,它计算训练样本的梯度和二阶导数,并根据这些信息构建一个新的决策树,用于拟合残差。
3) 优化弱学习器权重:XGBoost使用线性搜索方法为新的决策树找到最佳的权重,以便再将其添加到当前模型后最小化目标函数值。
4) 更新模型:将新决策树及其权重添加到当前模型中,然后更新模型的预测值。
5) 终止条件:当达到预设的迭代次数、目标函数收敛或无法进一步降低目标函数值时,算法停止迭代。
2.3.2 BP神经网络
BP神经网络算法主要包含输入层、隐含层以及输出层,其信号传递流程为:通过输入层对输入信号进行输出,使其经过隐含层到达输出层。BP神经网络算法的拓扑结构如图5所示。
模型建立的主要步骤共分为8个步骤[8]:①首先应完成BP算法中输入输出阈值、权值以及学习速率等变量的初始化,该算法的数据列为[(x,y)]。
②结合输入变量[x]、连接权值以及阈值对隐含层的输出进行计算,其公式为:
[Hj=f(i=1nωijxi-aj)j=1,2,...,l] (2)
式中:H代表的含义为BP神经网络算法的输出;[l和f]代表的含义为隐含层的节点数和激励函数,激励函数的公式为:
[f(x)=11+e-x] (3)
③完成BP神经网络算法预测值[O1]的计算,预测值[O1]的公式为:
[O1=j=1lHjωj1-b1] (4)