基于RAG的计算机类课程知识库构建及应用研究
作者: 刘珍亿
摘要:针对大语言模型在计算机类课程教学问答系统中面临的知识碎片化、动态更新迟滞及多模态资源整合不足等问题,该研究提出了一种基于检索增强生成(Retrieval-Augmented Generation, RAG) 的课程知识库系统构建方法。该方法旨在通过动态意图识别和混合检索策略算法,实现计算机类课程知识点的高效组织与精准服务。动态意图识别通过构建上下文感知的语义推理网络,实时解析用户查询中隐含的实践操作需求与知识拓扑关联,有效缓解传统方法对复合型教学意图的误判问题。混合检索策略融合了语义推理与跨模态对齐技术,采用动态权重分配机制,实现文本、操作流程等多源数据的协同检索。实验结果表明,基于RAG的混合检索方法相比纯大语言模型,在准确率和召回率上均有明显提升。
关键词:大语言模型;检索增强生成;知识库;多模态
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2025)08-0026-03
开放科学(资源服务) 标识码(OSID)
0 引言
计算机类课程具有知识迭代速度快、实践关联性强等特征,其教学资源通常涵盖教材文本、实验代码、操作视频等多模态数据。随着教育数字化转型的推进,课程资源呈现出碎片化分布特征,不同模态数据间的语义关联性与结构化程度差异显著。当前教育领域基于关键词的智能问答系统主要面临两方面的技术瓶颈:1) 传统检索方法在处理多模态数据时,受限于模态间的语义鸿沟与结构差异,难以实现跨模态资源的精准关联;2) 大语言模型(Large Language Model, LLM) 虽具备较强的生成能力,但其参数固化特性易导致知识时效性不足与领域幻觉问题。
本研究提出面向计算机类课程的混合检索策略,通过代码片段抽象语法树(Abstract Syntax Tree, AST) 的结构化表征与文本语义向量的跨模态对齐,实现编程逻辑与理论知识的协同检索,解决传统方法在代码语义解析与多模态资源关联中的精度损失问题。同时,设计基于RAG的教学问答系统,为教育场景下大模型与领域知识的深度耦合提供了技术路径。
1 理论基础
1.1 RAG
RAG(Retrieval-Augmented Generation,检索增强生成) 是自然语言处理领域的新型架构范式,主要包括检索模块和生成模块。其核心思想是通过外部知识检索机制提升生成模型的内容准确性与事实一致性。该范式通过信息检索系统与预训练语言模型的结合,在生成过程中动态检索相关领域文档作为上下文约束,有效缓解传统生成模型因参数固化导致的时效性不足与事实幻觉问题[1]。相比纯LLM,RAG能够借助本地知识库提升时效性与准确性。
1.2 本地知识库
本地知识库指部署在本地计算环境中的结构化或非结构化数据集合,专为特定组织或应用场景定制构建,具备领域专精性与数据可控性特征。通常整合企业内部文档、专业文献、操作日志等异构数据源,通过信息抽取、实体链接等技术转化为机器可读的知识图谱或向量化表示,支持语义检索、推理服务等智能化应用。与通用互联网知识库相比,其核心优势在于数据主权明确、隐私保护性强且更新维护机制自主可控。
2 计算机类课程知识库构建方法
2.1 多模态数据采集与处理
建立计算机课程知识库的过程中,需要对教材文本内容、教学视频、代码库中的程序实例以及学生实验文档等跨模态异构数据资源进行系统性整合与协同处理。通过自然语言处理技术解析课程文档,结合语音识别与关键帧提取技术处理视频内容,运用抽象语法树分析代码结构特征,并建立跨模态语义关联标注体系。数据清洗阶段重点解决格式不统一、信息冗余及噪声干扰问题,采用实体链接技术实现知识点与教学资源的精准映射,同时构建时序关联模型刻画课程内容的逻辑演进关系。
2.2 向量化与索引构建
向量化是将课程多模态资源(文本、代码、视频等) 转化为低维数值向量的技术过程,旨在通过深度学习模型提取其语义与结构特征。其核心是通过预训练语言模型、图神经网络及视觉编码器等技术,将非结构化数据映射至统一语义空间,形成机器可计算的稠密向量表征。向量化可突破关键词局限,实现精准语义检索,构建跨模态语义关联(如图文、代码) ,并借助压缩与近似索引技术,提升亿级数据检索效率。索引构建旨在高效组织高维向量数据,基于近似最近邻搜索(Approximate Nearest Neighbor, ANN) 、分层导航或量化编码技术建立索引结构,支持快速匹配与语义相似度计算,目标是加速向量的检索和查询[2]。
2.3 知识更新与质量控制
课程知识库的动态更新依赖自动化采集与人工审核的协同机制:为实时更新课程知识库,本系统采用定制化爬虫监控MOOC平台、课程官网等。检测到更新后触发增量抓取流程,并借助异构数据管道实现新版课件的实时解析与向量化。针对代码案例与实验步骤的更新,采用AST比对算法检测语法逻辑差异,结合HNSW(Hierarchical Navigable Small World graphs) 索引的增量扩展技术避免全量重建开销,同时基于课程版本元数据构建时序知识图谱,防止新旧概念冲突。
质量控制层面,设计双通道反馈闭环:教师端审核界面支持错误答案标记与知识点关联修正,系统通过主动学习策略将标注数据用于嵌入模型微调;学生端则部署知识冲突检测模块,利用预训练模型对用户提问与检索结果进行一致性验证,若检测到潜在矛盾,自动触发人工审核工单。
3 基于RAG的课程问答系统设计
3.1 系统架构
前端架构采用微信小程序或网页形式实现轻量化交互,后端架构则基于LangChain组件流水线构建,通过Flask框架封装Restful API服务[3]。系统采用分层处理架构,包含以下核心功能模块。
1) 输入预处理单元:对用户输入的问题进行清洗、分词、词性标注、实体识别等预处理操作。该单元输出结构化语义框架,为下游模块提供规范化输入表征,可有效降低后续模块处理语义歧义的负载。
2) 语义理解单元:运用深度学习模型对预处理后的文本进行语义分析,提取问题的关键信息和意图。通过集成预训练语言模型与领域适配机制,采用上下文感知编码器实现语义角色标注与意图分类双任务的协同学习。通过多头注意力机制建立跨层次语义关联,针对教学场景特别构建问题类型分类矩阵,并通过动态权重分配策略,有效处理专业术语的语境敏感解析。
3) 知识检索单元:根据语义理解结果,在课程知识库中查找相关信息。构建多源数据融合检索框架,包含结构化关系型数据库、向量化知识图谱及稠密检索模型。采用混合检索策略,结合特征匹配与余弦相似度计算,执行多跳推理检索路径优化。
4) 答案生成单元:结合知识检索结果,使用文本生成技术生成回答。对于简单事实型问题,可以直接返回检索结果;对于复杂问题,可能需要进行推理、融合多个信息源等操作。
3.2 核心算法设计
3.2.1 动态意图识别
动态意图识别作为知识库交互系统的核心算法,其设计需解决用户查询的多义性与上下文动态演化问题。该算法采用多模态输入联合建模策略,通过融合文本、代码片段及操作日志等多源数据,构建基于课程知识图谱的语义理解框架[4]。针对自然语言查询的模糊性,引入预训练语言模型与课程领域适配机制,利用对比学习在课程本体约束下生成细粒度意图向量。上下文感知模块采用时序图神经网络,动态跟踪用户历史交互路径与知识点关联强度,通过注意力机制捕捉当前查询与前期对话的语义连续性。为应对知识库更新引发的意图分布偏移,设计增量式在线学习架构,结合课程更新日志与用户反馈数据实现意图分类器的动态优化。算法实现时采用分层蒸馏策略,将大型预训练模型的知识迁移至轻量级意图识别网络,确保低延迟响应与高并发处理能力。
3.2.2 混合检索策略
混合检索策略采用异构特征协同机制,整合符号匹配与语义理解技术以优化多模态知识获取效能。系统构建双通道并行处理架构:一方面,针对结构化数据资源(如API文档、知识点关系表) 实施改进型稀疏检索方法,通过引入课程本体约束条件动态调整关键词权重分布,强化领域特定术语的匹配精度;另一方面,针对非结构化文本(如实验报告、技术讨论帖) ,部署课程领域适配的稠密向量检索模块,基于双塔式神经网络生成低维语义表征,结合量化索引技术实现大规模向量空间的快速相似度计算。在检索结果融合阶段,设计上下文感知的动态加权机制,通过轻量级门控网络分析查询语句的语法特征与语义完整性,自适应调节符号匹配得分与语义相似度值的整合比例。为降低跨模态检索延迟,系统构建知识单元导向的多级缓存结构,采用热度感知的替换策略优先保留高频访问内容,结合课程章节关联性预测实现缓存命中率优化[5]。
4 实验与结果
4.1 数据集与评估指标
实验数据集构建基于程序设计基础、数据库技术基础、计算机网络三门计算机核心课程的数字化资源,整合了1 268份课程文档(包括课件、实验手册、试题解析等结构化与非结构化文本) 及342个实验操作视频,形成了跨模态课程知识库。文档数据通过代码片段提取、公式解析与知识点关联挖掘完成了结构化处理,视频资源则通过每秒关键帧视觉特征抽取和语音转录生成了多模态表征。数据集按照7:2:1的比例划分为训练集(888份文档+239个视频) 、验证集(254份文档+68个视频) 和测试集(126份文档+35个视频) 。
本实验采用基于黄金标准集的二元相关性判定框架,针对检索系统返回的Top-10结果进行性能评估:
准确率(Precision) :返回结果中与查询真实相关的文档比例,计算公式为:相关文档检出数/总返回文档数,用于衡量系统抗噪声能力。
召回率(Recall) :标准答案集中被成功检索到的相关文档比例,计算公式为:相关文档检出数/总相关文档数,反映系统查全能力。
P值:在零假设成立的前提下,观测到当前极端结果的概率,通常用于判断实验结果是否具有统计显著性。当P值<0.05时,通常认为结果具有统计学意义(拒绝零假设) 。
4.2 结果对比
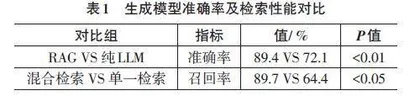
实验结果表明,基于RAG框架的增强方法较纯LLM生成模式在计算机类课程的1 500个查询样本上取得了显著性能提升,准确率由72.1%提升至89.4%;混合检索策略通过融合文本语义与视频时空特征,在标准测试集上的召回率达到了89.7%,较单一文本检索提升了25.3%,验证了多模态对齐机制的有效性。如表1所示。
5 结论与展望
本研究针对计算机专业课程资源检索中存在的模态割裂与语义鸿沟问题,提出了一种融合符号匹配与语义理解的混合检索框架,为教学课程知识库的智能化服务提供了有效解决方案。通过构建双通道异构特征处理机制与动态加权融合策略,系统实现了结构化文档与非结构化资源的协同检索,显著提升了跨模态查询的意图理解精度。研究成果对教育资源的数字化管理、个性化学习支持系统的开发具有实际应用价值,为多模态教育知识库的构建提供了方法论参考。
当前方法在跨模态语义对齐深度、实时视频特征提取效率方面仍存在优化空间。未来工作将重点探索两方面的突破:首先,引入多模态大模型(如GPT-4V) 的视觉-文本联合编码能力,强化视频操作步骤与代码逻辑的时空关联建模;其次,构建教育智能体协同框架,通过智能体分工机制实现知识采集、质量校验与服务响应的全流程自动化,推动教学支持系统向自主化、自适应方向演进。
参考文献:
[1] 张力军,刘偲,廖纪童,等.基于大模型检索增强生成的计算机网络实验课程问答系统设计与实现[J].实验技术与管理,2024,41(12):186-192.
[2] 梅忆寒,王琳琳,王鹏飞,等.基于多模态与检索增强生成的数据库知识问答系统[J].计算机教育,2024(12): 232-237.
[3] 窦凤岐,胡珊,李佳隆,等.基于LangChain的RAG问答系统设计与实现:以C语言课程问答系统为例[J].信息与电脑(理论版),2024,36(6):101-103.
[4] 汤博文,马名轩,张以宁,等.基于意图识别与检索增强生成的校园问答系统[J].通信学报, 2024, 45 (S2): 255-261.
[5] 高雅奇.基于大语言模型和RAG技术的高校知识库智能问答系统构建与评价[J].电脑知识与技术,2024,20(29):18-20,38.
【通联编辑:代影】