面向火焰检测的轻量化维度注意力卷积YOLOv5s方法
作者: 井望
摘要:针对YOLOv5s在复杂背景下难以提取火焰细节特征的问题,本文构建了一种轻量化维度注意力卷积模块。该模块采用分组异构卷积块,在保证模型轻量化的同时提取火焰特征,并在其分支网络上加入轻量化维度注意力机制,增强模型对重要特征的关注,抑制噪声信息的干扰。将该模块集成至YOLOv5s后进行多次实验,实验结果表明,所构建的模块在保持模型轻量化的同时,显著提高了检测精确度,mAP50指标增加了6.9%,mAP50-95指标增加了6.6%。
关键词:YOLOv5s;火焰检测;轻量化维度注意力卷积;分支网络;特征提取
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2025)08-0022-04
开放科学(资源服务) 标识码(OSID)
0 引言
近些年,火灾的防范日益受到人们的重视,特别是在人员密集场所,一旦发生火灾,将会对人们的生命财产安全造成极大的损失。因此,在火灾防范过程中,如何快速有效地检测出早期火灾信号成为亟待解决的问题之一。
对于火灾的防范措施,传统的监测手段包括人工巡查、温度传感器、烟雾传感器和光传感器等方法[1]。虽然这些方法在实施过程中在一定程度上能够实现火灾的早期发现,但存在成本较高、传感器安装困难和检测精确性欠佳等问题,因此限制了它们的广泛应用。
随着计算机视觉技术的快速发展,特别是基于深度学习技术的火灾检测方法逐渐被广泛应用,主要原因在于该方法具有检测速度快、灵敏度高和易于实现等优点。在基于深度学习技术的火灾检测中,主要任务是对火焰或烟雾进行视觉检测。其中,火焰的检测方法可以分为基于火焰图像分类和基于火焰检测两类。
在基于火焰图像分类的方法中,研究者主要采用人工特征提取[2]、卷积神经网络[3-5]、Transformer[6]等方法进行火焰图像的分类。例如,丁毓峰等人[2]利用人工特征提取方法对火焰和烟雾的形态、纹理等进行特征提取,构成特征向量,然后将其输入到一种单隐层前馈神经网络中完成火焰烟雾图像的分类;颜佳文等人[5]提出了一种基于改进型VGG网络的火焰图像识别方法,通过基于批标准化层的结构化剪枝技术对VGG网络进行轻量化处理,大幅降低了模型的参数量;梁秀满等人[6]通过一种基于CNN-Transformer双流网络模型对烧结火焰进行识别,采用两种不同的网络模型提取烧结火焰的特征,实现烧结火焰分类的目的;Almeida等人[3]提出了一种基于轻量级卷积神经网络的野火识别方法,该方法通过对卷积神经网络的优化,使其能够更好地在边缘设备中使用;Nguyen等人[4]提出了一种融合了注意力机制的火焰图像识别方法,该方法将轻量化卷积和注意力机制相结合,在火焰识别任务中表现出色。
而在基于火焰检测的方法中,研究者主要使用Faster R-CNN[7]、YOLO[8]等方法对图像中的火焰部分进行识别检测,并将火焰进行框选,从而实现检测和识别火焰的目的。例如,Barmpoutis等人[9]将Faster R-CNN与基于LDS(线性动态系统,Linear Dynamical Systems,简称LDS) 的多纹理分析相结合,以实现较高精度的火焰检测;姚艺莲等人[10]提出了一种基于YOLOv5的轻量级火焰实时检测方法,通过多种轻量化技术和注意力机制提升了检测精度;王雷等人[11]通过替换YOLOv3中的Darknet-53结构和采用空洞卷积,实现了较高的检测精度和检测速度。
尽管已有多种轻量化火焰检测方法被提出,并在实验中展现了较为优异的性能,但如何进一步优化火焰检测方法以适应更为复杂的环境依然是一个难点。因此,本文选取YOLOv5s[12]作为基线方法,对其进行改进和优化,以提升其在复杂环境下的检测性能。选取YOLOv5s的原因在于其网络模型在各种应用场景中均表现出较为稳定的性能,因此对其进行改进和优化,可以更好地应用于各种复杂环境下的火焰检测。
总体上,本文的工作如下:1) 采用了一种轻量化维度注意力机制,以增强模型对复杂环境下火焰特征的关注能力,在保证模型轻量化的同时提高了模型的检测精度;2) 对YOLOv5s中的部分卷积模块进行优化改进,构建了一种轻量化维度注意力卷积模块,在显著提升模型检测精确度的同时降低了模型的参数量;3) 利用复杂场景下的火焰数据集对改进优化后的模型进行多次消融实验,以实验证明方法的有效性。
1 方法改进
基线方法YOLOv5s虽然可以广泛用于各种场景,特别是用于火焰的实时检测,但其模型结构中的部分卷积块存在难以提取火焰细节特征的问题。因此,本文对其进行优化改进,构建了一种轻量化维度注意力卷积YOLOv5s(Lightweight Dimension Attention Convolutional YOLOv5s,简称LDAC-YOLOv5s) ,旨在进一步提升YOLOv5s在火焰检测中的性能。
1.1 轻量化维度注意力机制
对于通过RGB摄像头获取的火焰图像,其火焰特征极易受到光照、背景参照物、角度等因素的不利影响。针对上述问题,本文受TA思想[13]和CA思想[14]的启发,采用了一种即插即用的轻量化维度注意力机制(Lightweight Dimensional Attention Mechanism,简称LDAM) ,以帮助模型在训练时更容易提取火焰的重要特征。
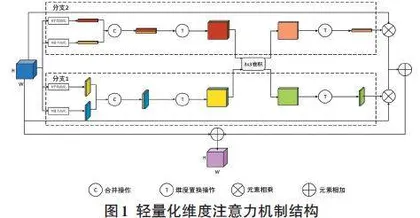
LDAM的总体结构如图1所示。在LDAM中,本文重点采用相同权重的3×3卷积核来帮助模型关注不同维度下的火焰重要特征,其具体步骤如下,1) 维度池化。采用维度全局平均池化(Dimension Global Average Pooling,DGAP) 和维度全局最大池化(Dimension Global Max Pooling,DGMP) 分别对输入的特征图进行池化处理,以提取H(纵向) 维度和W(横向) 维度下的全局特征;2) 特征合并。将相同维度下的特征图进行合并,并通过维度置换的方式输入至3×3卷积层中,以实现特征的合并提取;3) 权重特征图生成。采用权重相同的3×3卷积核对不同维度下的火焰特征进行自适应提取,并生成相应的权重特征图;4) 特征图处理。将卷积层输出的两组权重特征图经维度置换后与原始特征图进行元素相乘,得到两组特征图;5) 输出整合。将处理后的两组特征图进行元素相加,作为LDAM的最终输出。
通过LDAM,模型可以更加关注火焰的重要特征,从而实现进一步提升模型检测精度的目的。
1.2 轻量化维度注意力卷积模块
YOLOv5s中的部分卷积模块采用传统卷积方法,尽管可以实现特征的提取,但在复杂场景下对火焰特征的提取能力有限。此外,其部分卷积层的步长设置为2,这会使模型忽略一些重要的细节特征。针对上述问题,本文受分组卷积[15]思想和InceptionNet[16]思想的启发,在LDAM基础之上构建出一种轻量化维度注意力卷积模块(Lightweight Dimensional Attention Convolutional Module,LDACM) 。LDACM的设计目标是提升模型的特征提取能力,同时控制计算量和参数量,确保模型具有轻量化。具体的LDACM结构如图2所示。
对于LDACM,其具体组成部分包括如下,1) 特征图拼接:在对原始特征图进行特征提取之前,需对特征图进行通道维度分组,然后对分为两组的特征图进行横向维度拼接,以促进不同组之间的信息交流;2) 并联卷积层:在原有的常规卷积层基础之上,并联一个3×3的卷积层,其步长固定为1,以达到更好学习火焰特征的目的,避免其细节信息的丢失;3) 注意力机制:为进一步提取火焰的细节特征,本文在分支2网络中加入LDAM注意力机制,以促进模型检测性能的进一步提高;4) 特征融合:每个分支网络输出的特征图进行维度重构,重构成横向维度和纵向维度均为1的特征张量。进行上述操作后,再将两组张量进行横向拼接,经平均池化后完成分支网络的特征融合;5) 特征图输出:对于完成特征融合的张量进行维度重构,重构成一组特征图作为输出。
总体上,上述结构不仅帮助模型进一步提取火焰的细节特征,也在一定程度上保证了模型的轻量化。这里需要注意的是,在LDACM中的K×K卷积是原YOLOv5s中所采用的卷积核大小,每层卷积核的大小并不固定。除此之外,卷积层中还包含了SiLU激活函数[17]和批标准化层[18]。为保证分支1和分支2输出的特征图大小一致,因此在分支2的3×3卷积层之前加入一个平均池化层。
2 实验结果及分析
2.1 实验数据集
本文实验所采用的火焰数据集可分为两部分,一部分为通过网络收集的火焰图片;另一部分为本文自行采集的火焰图片,两部分合计共10 431张图片。其中,训练集为8 037张图片,验证集为2 394张图片。数据集涵盖了各种场景,包括室内外场景,如客厅、学校教室、停车场、森林等。
对于火焰图片的标注,采用Labelimg工具进行标注,标签格式为txt。在模型训练和验证时,图片分辨率统一设置为640×640。
2.2 实验环境配置
硬件平台配置如下:CPU为英特尔I5-9400F;GPU为英伟达RTX 4060Ti(8GB) ;内存为DDR4 32GB。
软件平台配置如下:操作系统为Ubuntu 22.04 LTS;编程语言为Python 3.10;深度学习框架为Pytorch 2.2.0(CUDA版) ;GPU加速框架为CUDA 12.3;其他依赖库包括Torchvision 0.17.0、Torchaudio 2.2.0等。
为验证本文方法的有效性,以YOLOv5s作为基线方法,并进行多次消融实验。训练周期均设置为50 epochs。为避免超参数差异对实验结果产生影响,本文所采用的其他超参数设置与基线方法YOLOv5s模型提供的超参数一致[12],因此不再赘述。
2.3 实验评价指标
对于实验中的模型性能评价指标,本文采用了模型复杂度指标和模型检测精确度指标。模型复杂度包含模型参数量Parameters(单位为百万) 和模型计算量FLOPs(单位为十亿) 。模型检测精确度包含mAP50指标(IOU阈值在50%的平均精度) 和mAP50-95指标(IOU阈值在50%到95%的平均精度) 。对于模型复杂度的两个指标,其值越大表明模型越复杂,值越小表明模型轻量化程度越高;对于模型检测精确度的两个指标,其值越大表明模型的检测精确度越高,值越小表明模型的检测精确度越低。
2.4 消融实验
表1展示了基线方法YOLOv5s与改进方法LDAC-YOLOv5s在模型参数量、计算量以及检测精确度方面的对比。实验结果表明,加入LDACM后,模型参数量降低了约12.8%,尽管计算量略有增加(上升了约5.7%) ,但其检测精确度显著提升,mAP50提升6.9%,mAP50-95提升6.6%。这表明改进后的模型更能专注于火焰重要特征的学习,使得其学习效率更高。
表2的实验结果表明,单独应用横向维度注意力机制(LDACW) 或纵向维度注意力机制(LDACH) 时,均能使模型在mAP50和mAP50-95两种指标上有所提升。然而,当两者结合使用时,其检测精确度进一步提高,mAP50提升至76.6%,mAP50-95提升至42.0%。这表明,在使用双向维度注意力机制时,模型能更加准确地关注火焰重要特征,从而提升模型检测性能。
表3的实验结果表明,使用张量拼接方法(LDACY-YOLOv5s) 相比于不使用张量拼接方法(LDACN-YOLOv5s) ,其模型在mAP50指标和mAP50-95指标上分别提升了1.4%和1.3%。其背后的原因在于张量拼接有效促进了不同组特征图之间的信息交流,提升了模型的特征提取能力。该方法虽然使模型在计算量方面有所增加,但在参数量方面保持了不变。
在表4中,本文针对LDACM中使用不同类型的池化方法对模型是否造成影响进行了相应实验,以验证加入平均池化方法的有效性。实验结果表明,相比于加入最大池化,在使用平均池化时,模型的mAP50指标和mAP50-95指标均有所提升,mAP50指标上升了1.3%,mAP50-95指标上升了1.7%。检测精度上升的原因在于,使用平均池化可以有效抑制部分噪声对模型训练的影响,同时使模型在训练过程中更容易学习到火焰的重要特征。