大模型开闭源之争
作者: 吴俊宇 徐文璞
今年以来,中美两国AI(人工智能)产业的企业家、投资者、创业者同时掀起了一场争论:大模型到底应该开源,还是应该闭源。
在中国,争论的焦点人物是百度创始人李彦宏。今年4月他公开表示,“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。开源模型会越来越落后。”这一观点不乏反对声音。反对者包括阿里云CTO(首席技术官)周靖人、百川智能CEO(首席执行官)王小川、猎豹移动CEO傅盛。今年5月周靖人在一次媒体群访中直言,“开源对全球技术及生态的贡献毋庸置疑。这在全球范围内被多次证明,已经没有再讨论的必要。”
在美国,争论更激烈。特斯拉创始人马斯克一度起诉AI创业公司OpenAI。马斯克2015年曾是OpenAI主要创始人、投资人之一。他认为,现任CEO奥特曼领导的OpenAI违背了“以非营利组织运作,要让AI开源开放”的承诺。硅谷两位著名投资者,a16z创始人安德里森、凯鹏华盈创始人柯斯拉在社交媒体多轮交锋。前者认为闭源模型会导致巨头垄断,破坏学术研究。后者认为大模型是经济武器,不应该开源。
开源,是一种软件开发模式——源代码免费公布,靠社区捐赠存活。开发者可以自由下载、修改、分发,反馈软件Bug(软件缺陷或错误),提出优化建议。这种集体创新会加速软件迭代。开源模型指可免费使用、公布了模型参数等技术细节的模型;闭源模型指要付费且未公布技术细节的模型。简单理解,开源约等于免费,但要自己买菜做饭;闭源约等于付费,相当于去餐厅吃饭,能有更好的服务。
大模型到底应该开源,还是应该闭源?其中掺杂了商业利益、技术观点等因素,以至于很多事实被混淆了——但这场争论背后有几个确定的事实。
其一,不同的商业策略,让企业选择了不同的技术路线。百度、OpenAI等希望大模型业务快速商业化的企业,选择了闭源;阿里云、Meta等靠云计算或广告业务盈利的企业,选择开源做大蛋糕。
其二,开源、闭源两种市场需求会长期共存,无法简单判断孰优孰劣。开源、闭源模型有各自的适用场景,选择哪种模型和市场需求有关。这不会随模型厂商的意志而变化。
其三,开源模型、开源软件有本质区别。开源软件公布了源代码和大部分技术细节。开源模型更像一个免费的技术黑箱——开放了模型参数,但很少开放源代码、训练数据、训练过程等技术细节。
另外,中国AI产业的开闭源之争,更多是商业竞争。开源无国界,这个理念已经被普遍认同。但在中美AI产业博弈加剧的背景下,美国产业界反对开源的声音越来越大。
谁在开源,谁在闭源?
大模型发展尚处早期,仍需探索试错。开源、闭源并非泾渭分明。企业面对开源、闭源的选择题时,走出了三条不同的路。
最极端的是,只做开源模型。走这条路的企业比较少,Meta是少数之一。好处是会吸引更多用户,问题是没有盈利模式,只有大公司烧得起。
Meta旗下的Llama 3是全球用户最多的开源模型。Meta的主营业务是社交媒体(如Facebook、Instagram),2023年净利润高达390亿美元。Meta既有探索新业务的冲动,又没有靠模型盈利的压力。因此,它可以只做开源模型,暂时不考虑盈利问题。
一条中间路线是开源、闭源并行,这条路很灵活。企业既能靠开源获取用户,又能靠闭源获取收入;既给了开发者选择空间,企业自己也有容错空间。
选这条路的企业包括微软、谷歌、阿里云、腾讯云,以及Mistral Al、智谱AI、百川智能等AI创业公司。开源、闭源并行的常见做法是,用免费的开源模型吸引用户,引导用户使用尺寸更大、性能更强的闭源模型。比如,微软主力商业化模型是OpenAI旗下的GPT-4系列,但也开源了小模型Phi-3 Mini;阿里云开源了5亿-1100亿参数的十余款模型,还同时提供闭源的基础大模型、行业模型;谷歌开源了Gemma系列小模型,还提供闭源的Gemini系列基础大模型;Mistral Al等创业公司开源了上代性能落后的模型,引导用户付费使用本代性能更强的模型。
表1:中国、国际知名模型和开源情况
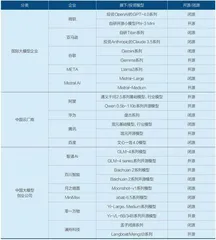
开源、闭源并行的问题是,商业化有时会左右手互搏。一些客户用了免费的开源模型,就不会再用付费的闭源模型。模型厂商会因此失去一部分收入。
一位中国AI软件服务商技术人士今年7月对《财经》表示,他们近期用阿里云的通义千问开源模型(Qwen2)二次训练微调,服务了一个地方城市旅游局。这笔订单超过千万元,他们是受益者,但阿里云没有收入。《财经》查询了Github(全球最大代码托管平台)上Qwen2的许可协议。协议显示“无需提交商业使用请求”。也就是说,Qwen2被训练微调后商用无需付费。
开源的长远价值是做大模型市场蛋糕。一位阿里云人士对《财经》表示,用户修改开源模型拿去商用很正常,做开源就要有这个准备。阿里云虽然暂时没有吃到所有蛋糕,但做大了行业蛋糕。长期来看,最终还是会受益。大模型被政府、大中小企业、开发者等不同客户广泛使用时,才会出现化学反应。大模型产业要建立生态,形成增长飞轮。阿里云旗下AI开源社区魔搭ModelScope可以看到这一趋势。截至今年7月,魔搭社区有超过560万开发者,5500多款优质模型和上千数据集,是中国最大的开源模型社区。
一种更乐观的观点认为,开源、闭源甚至可以成上下游关系。开源在技术上游,负责社区参与、技术迭代、吸引客户,确保技术领先同行。闭源在下游,负责商业变现。
澜舟科技是一家中国大模型创业公司。澜舟科技合伙人、联席CEO李京梅对《财经》表示,开源是技术策略也是商业策略。它可以影响开发者社区,也可以影响潜在客户技术团队的心智。开源和闭源不矛盾。闭源模型客户反馈周期相对较长,但开源模型的社区开发者会很快给到反馈。这可以帮公司快速迭代产品。
一位中国头部科技企业的AI战略规划人士认为,对阿里云这类头部云厂商来说,开源、闭源并行比只做闭源好。阿里云收入主要来自公共云四大件(计算、存储、网络、数据库)。免费的开源模型会促进客户业务数据消耗,进而带动上述基础云产品的销售。
只做闭源模型,这条路简单直接、逻辑清晰。走这条路线的大公司认为,大模型要商业化,就必须闭源,否则无法商业闭环。
AI创业公司OpenAI(旗下GPT-4系列模型)、亚马逊(投资了AI创业公司Anthropic,旗下包括Claude 3.5系列模型)、华为(盘古大模型)、百度(文心大模型)等企业都选了这条路。企业使用大模型通常按API(应用程序编程接口)调用次数付费,这就像为水电煤按使用量缴费。闭源模型的商业模式理论上是最健康的。微软Azure、亚马逊AWS、谷歌云近一年营收增速都提升了5个百分点左右,利润水平也略有提升。这被认为是大模型拉动的结果。
但在中国,闭源模型短期内很难真正盈利。今年5月中国模型市场开始价格战。降价目的是激发客户需求,做大市场规模。字节跳动旗下云服务火山引擎、阿里云、腾讯云、百度智能云先后把大模型调用价格下降了90%以上。大模型调用毛利率从超过60%下滑至低于0%。
表2:斯坦福大学基础模型研究中心全球大模型综合性能排名

一位中国云厂商大模型业务负责人认为,大模型调用进入了“负毛利时代”。使用次数越多,亏损就越大。区别是,阿里、字节跳动、百度这些大厂亏得起,中小企业、创业公司亏不起。
他和一位大模型创业公司高管表达了类似的观点——不同公司基因不同,模型商业策略也不同。云是阿里云的核心业务,模型开源的最终目的是卖更多云。火山引擎背靠字节跳动,母公司广告业务可以输血。火山引擎在云计算市场份额远低于阿里云,“光脚不怕穿鞋的”,希望通过价格战抢占更多市场份额。AI是百度的核心业务,百度希望靠大模型盈利,所以强调闭源模型的价值。
争论是什么?共识是什么?
中国的大模型开闭源之争,有几个焦点:其一,开源模型和开源软件是否有区别?其二,开源模型和闭源模型,谁更强?其三,开源模型和闭源模型,谁更贵?
第一个争论,开源模型和开源软件是否有区别?答案是,区别很大。绝大部分开源模型并没有完全开源。它们更像是可以免费使用的黑箱,而不像开源软件一样是个透明的盒子。
开源软件会公布源代码,开发者能通过源代码掌握软件的大部分技术细节。开源软件免费的核心逻辑是,全社会的开发者可以帮助软件厂商找产品Bug、提优化建议。社会化开发,不仅可以降低软件的研发成本,还能加快软件的迭代速度。手机操作系统安卓、数据库软件MySQL都是靠这种方式取得了成功。
开源模型的复杂性远超开源软件,可开源的项目包括源代码、参数权重、模型结构、训练数据、训练过程等。荷兰拉德堡德大学两位学者,利森菲尔德、丁格曼斯今年3月发表论文,对比了开源模型的开源程度。论文显示,性能最强的开源模型通常只会开源参数权重。一种解释是,模型厂商为确保模型性能领先,不能把“配方”全盘托出。以全球性能最强的开源模型Llama3为例,它只部分开源了参数权重和模型结构,源代码、训练数据、训练过程均未开源。
开源理念对产业生态的价值毋庸置疑。百度智能云AI与大模型平台总经理忻舟今年7月对《财经》表示,开源模型会让模型应用、行业模型变得更丰富。但他反对将开源模型和开源软件混为一谈。因为两者存在本质区别——开源模型无法像开源软件一样,靠社会开发者参与提升产品性能、降低研发成本。基座模型只能靠模型厂商自己训练而提升,开源模型精调、推理优化都不及商业模型,对开发者技术要求很高,实际使用成本并不低。
图1:开源模型和闭源模型的技术差距在缩小
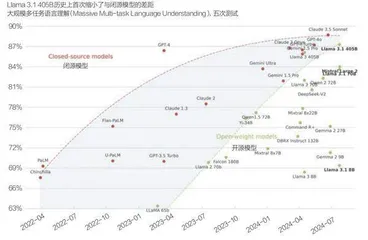
第二个争论,开源模型和闭源模型,谁更强?事实是,闭源模型性能通常比开源模型更强,但开源模型和闭源模型的性能差距在缩小。