基于大数据文本挖掘技术对幼小衔接舆论的批判性话语分析
作者: 李娟 陆露 彭小媚 曾毅 王舒琦
[摘 要] 推动幼小衔接工作的科学开展是当前政府教育治理的重要内容。本研究运用大数据文本挖掘技术,选出新浪微博中热度最高的5个官方媒体博文中与《教育部关于大力推进幼儿园与小学科学衔接的指导意见》有关的30 614条大众评论为研究对象,从文本内容、话语实践、社会实践三个方面对其进行批判性话语分析。结果显示受既往政策实践和社会文化的影响,大众对幼小衔接的认识还处于感性认知阶段,如过度关注幼儿在学业方面的衔接,过于担心孩子因为没有提前学习相关知识而到了小学不适应,甚至影响将来的升学,同时过分强调政府、小学和幼儿园的主体责任,而没有正视家长在幼小衔接中的作用。这在一定程度上会阻碍幼小衔接政策的有效实施,并对幼儿的发展造成负面影响。政府应重视幼小衔接政策的社会宣传,采用多种政策工具落实相关政策,完善相关家庭教育服务体系。
[关键词] 幼小衔接;大众评论;文本挖掘技术;批判性话语分析
一、问题提出
幼小衔接是幼儿园和小学循序渐进促进幼儿成长的过程。[1]幼小衔接工作的好坏直接影响着幼儿身心各方面是否能健康发展。[2]有研究表明,不当的幼小衔接会对幼儿的学业成绩、社会能力以及未来的社会成就等产生重大影响。[3][4][5]近年来,我国各级教育行政部门对幼小衔接问题高度重视。从出台教育指南意见到颁布教育规范、开展专项整治工作,再到提出促进幼儿园和小学双向衔接的指导意见,都体现了政府对加强幼儿园和小学教育科学衔接的迫切愿望。
生态系统理论为幼小衔接工作的科学开展提供了强有力的理论支持。布朗芬布伦纳将个体生活的社会环境看作一个有机整体,强调对个体的研究不仅要重视与其自身息息相关的主体的影响,同时还要综合考虑社会背景、文化、政策等多方面的因素。[6]2000年,美国学者雷姆·考夫曼(Rimm-Kaufman)等人基于生态系统理论提出了生态学动态幼小衔接模型。[7]该模型认为,幼小衔接是一个长期、多层次、复杂的过程,不同社会文化背景下的家长、学校、教师等大众视角都应该被考虑到。[8]幼小衔接的环境、家长压力的应对机制[9]以及不同利益相关者对幼小衔接的态度、价值观等因素都会影响幼小衔接的实践过程,进而影响幼儿在学校的早期表现。[10]因此,近年来开始有一些研究聚焦幼小衔接中的不同利益相关者,考察他们在幼小衔接方面的教育观念与行为,以期推进幼小衔接的科学开展。但这些研究所采用的方法大多是问卷法或访谈法,这两种方法都具有一定的局限性。问卷法通过设置相关问题诱发家长回答来获取这一群体的认识,这使得家长有可能在社会赞许等心理暗示之下没有真实作答,从而影响研究结论的客观性。另外,由于研究条件的限制,已有研究的样本范围也存在一定局限。[11]访谈法虽然可以收集更为深入的数据,但耗时耗力,难以收集到大样本数据,从而限制了研究结论的推广。当前,随着信息技术与文献计量方法的发展而出现的大数据文本挖掘技术可以在一定程度上弥补传统问卷法与访谈法的不足。随着网络社交平台的发展与普及,借助有关平台发表自己对当前热点事件的看法、感受与体验已经成为现代社会大众生活中的重要内容。这种即时发表的言论或评论通常是主体当下真实心声的反映,对围绕某一热点事件的大众言论或评论进行分析,可以廓清大众对这一热点事件的基本认识。
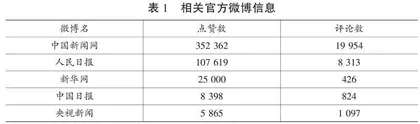
2021年4月9日,《教育部关于大力推进幼儿园与小学科学衔接的指导意见》(以下简称《指导意见》)一出台便吸引了社会大众的关注,成为当日新浪微博热搜榜第一名,幼小衔接相关内容迅速成为大众讨论的热点,中国新闻网、人民日报等官方媒体竞相报道,引发了大众的热烈讨论。以中国新闻网微博为例,该微博当日点赞数高达352 362次,转发数为6 484次,评论数为19 954条。短时间内井喷式的评论表明,大众对这一政策的出台极为关注,纷纷在这些平台上发表自己的见解,对幼小衔接提出自己真实的意见和困惑。这为研究者运用大数据文本挖掘技术对大众围绕《指导意见》发表的网络言论或评论进行分析提供了条件。本研究根据热度排序,筛选出5个热度最高的官方微博账号下30 614条针对《指导意见》的评论作为研究对象进行数据挖掘。与此同时,由于幼小衔接问题是一个社会问题,涉及多类主体,大众的评论具有一定的情境性。因此,研究者结合幼小衔接工作的实践背景,依据费尔克拉夫批判性话语分析法的三个维度,从文本分析、话语实践、社会实践三方面出发,对微博上的大众评论进行综合分析,挖掘话语背后隐藏的真实含义,深入考察不同利益相关者对《指导意见》这一政策的看法,并对促进幼小衔接工作的科学开展提出相应的对策和建议。
二、研究方法
(一)研究对象
本研究的数据资料来源于新浪微博客户端中与《指导意见》相关新闻热度最高的5个官方媒体博文的评论。本研究的数据基础是通过Python网络爬虫获取所得,其主要步骤如下。首先,输入搜索词“关于大力推进幼儿园与小学科学衔接的指导意见”定位至相关微博,根据热度排序筛选出5个热度最高的官方微博下的相关新闻。(见表1)其次,通过Python编写的网络爬虫程序将这些微博的正文内容、发布者信息、发布时间、点赞数以及评论数采集下来,形成宏观上的微博数据库。新闻的选择是由其点赞数和评论数决定的,因为点赞数和评论数可以说明大众对这一事件的关注度,评论内容则可以代表大众群体的一般观点。最后,利用网络爬虫采集相应微博的大众评论,对其进行数据过滤和去噪处理,所得评论为本研究的研究对象。
(二)研究工具
大数据文本挖掘技术主要是指在真实的海量数据中快速采集有用数据信息,并通过利用相应机器学习算法来挖掘隐藏在海量数据后面的信息。其技术主要包含两个方面,即大数据和文本挖掘。其中大数据是指满足4V特征的难以通过人工完成收集的数据,文本挖掘则是指对数据信息的提取。[12]本研究以Python为编程方法,运用Scrapy爬虫工具、Jieba中文分词工具以及TextRank算法,从有关《指导意见》的大众评论数据中提取关键词,以完成大众评论文本的挖掘任务。
1. Scrapy爬虫工具。
Scrapy是一套简单、高效的爬虫框架,它基于Python语言编写开发而成。Scrapy包含Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spiders(蜘蛛)、Item Pipeline(项目管道)等几个模块。[13]Scrapy的优势是可以在Twisted异步网络数据库的基础上交替执行多项任务,以此来实现对网络中海量数据的提取。[14]本研究的数据处理流程如下:第一步,研究者编写程序规则自动抓取相关网页信息,由Engine打开指定的网页,并将网页Uniform Resource Locators(统一资源定位器,简称URL)返回给Scrapy;第二步,Engine向Scheduler请求打开下一个网页的URL,并进行循环;第三步,由Downloader接受网页的URL,并将网页内容下载下来,下载完成后通过Downloader middlewares(下载器中间件)发送给Engine,再一次进行循环。在这个过程中,Engine将爬虫结果发给Item Pipeline(项目管道),Scheduler不断发送新任务给Engine,直到任务完成。[15]
2. Jieba中文分词工具。
Jieba中文分词工具是目前被广泛使用的一种分词工具,它是由国内程序员利用Python研发的中文分词库。[16]程序员基于人民日报等语料数据进行分析训练,建立起一个名为“dict.txt”的词典。该词典包含两万多个中文字词,并且根据语料训练统计出每个字词的词频和词性。[17]本文根据jieba程序包对文本数据进行分词。
3. TextRank算法。
TextRank算法是一种基于图论理论的关键词提取方法,它由谷歌公司提出的网页排名算法PageRank衍生而来。[18]TextRank算法主要经历以下三个步骤。首先,进行中文分词,构建选词合集。其次,进行参数设置,构建文本图模型。这个环节类似投票,词与词之间进行相互投票,经过不断迭代,每个词会趋于稳定,投票数越多的词就会被认为是关键词。[19]最后,进行关键词的排序与提取。
(三)研究过程
1. 数据采集。
研究者通过Python编写网络程序,运用Scrapy爬虫工具从新浪微博中搜索2021年4月9日发布了有关《指导意见》主题内容的相关媒体,筛选出热度最高的五大官方媒体博文,挖掘这些微博下的大众评论,最终收集到30 614条相关评论。(见图1)
2. 数据清洗。
通过初步观察网络爬虫采集到的微博评论数据,研究者发现数据存在噪声,如不含实际内容的微博、与具体问题无关的微博以及广告等无意义内容,这不仅为研究者理解语义带来了困难,而且还降低了中文分词和关键词提取的效率。因此,研究者对数据进行了清洗。首先,研究者对这些评论进行去噪处理,删除无意义词语,过滤垃圾评论。该步骤主要是为了保证数据的合理性。其次,研究者对数据进行了人工介入,进一步检查并去除无意义的、具有干扰性的评论,以保证文本挖掘任务的精确度。
3. 数据挖掘。
该环节主要是挖掘大众对“幼小衔接”问题关注的重点。这一环节通过新浪微博大众评论来获取相关信息,并以关键词的形式体现出来,它可以使研究者在大体上把握大众的讨论热点。当去噪处理完成后,研究者使用中文分词Jieba库,并通过Python实现中文分词。(见表2)
数据表明,初步分词结果并不是很理想,“了要”“得上”“损哒”“就让”等词语降低了中文分词的效率和准确率。为了解决这一问题,研究者引入了停止词字典。该字典用于过滤掉一些没有实质意义的词语,如副词、语气词、标点符号、错别字等。(见表3)
通过使用停止词过滤掉无意义词语,研究所得到的中文分词结果的准确率将会得到一定程度的提升。研究者在上述中文分词的基础上,进一步使用TextRank算法进行关键词选择。(见表4)
(四)数据处理
在得到关于《指导意见》大众评论的关键词之后,研究者使用费尔克拉夫批判性话语分析法对数据进行分析。费尔克拉夫(Fairclough)认为批判性话语分析法的主要作用是从社会文化背景中探究和解读话语文本的真实含义,揭示话语对于社会的建构性作用。[20]批判性话语分析的实质就是透过话语文本词汇、句法、语篇的本质去探索语言背后所隐藏的更深层次的意义。[21]费尔克拉夫把批判性话语分析法分为三个向度。第一向度是文本分析,即对话语的基本结构进行分析。第二向度是话语实践分析,它包括话语生成、传播和接受三个方面。第三向度是社会实践分析,即基于社会文化背景和意识形态分析话语所隐含的社会现实和社会结构。[22]
本研究从费尔克拉夫批评话语分析法的三维框架出发,以五大官方媒体微博下有关《指导意见》新闻的大众评论话语为研究对象,从文本分析、话语实践分析、社会实践分析三个角度对大众评论进行研究。其中,文本分析主要用于探究大众评论话语的关键词和句式特征;话语实践分析用于挖掘大众舆论生产及传播的原因,探究幼小衔接现状以及焦虑评论话语的成因;社会实践分析则用于探究有关大众评论产生于什么样的社会背景之中。
三、研究结果与分析
(一)大众评论的文本分析
费尔克拉夫认为:“‘话语’是一种对主题或者目标的谈论方式,包括口语、书面语言以及其他表达方式。”[23]基于网络文本的话语分析能够深层次地捕捉网络舆论之中大众对于某一社会事件的看法,它通常包括对文本词汇、语法、语篇结构的微观分析。考虑到大众评论不是大篇幅的文本内容,本研究主要对关于《指导意见》新闻的大众舆论的关键词进行分析,统计关键词的词频,并对大众评论中出现频率最高的关键词予以记录,将得到的统计结果作为大众评论的代表性结果。同时为了使数据具有可视化效果,本研究将结果以词云图的形式予以展示。(见图2)根据词云图所呈现的结果,本研究将大众评论的重点信息通过以下三个方面表示。