基于多维聚类的语体研究热点与发展趋势探赜
作者: 尉薇
[关键词] 语体;多维特征;系统聚类;知识图谱;热点趋势
[摘 要] 本文对2013—2022年的语体研究进行知识图谱可视化分析,从1905篇CNKI中文学术期刊数据库的语体研究论文中提取出35个高频核心关键词,在此基础上依次进行词频矩阵分析、相异系数矩阵分析、系统聚类分析和多维尺度分析等数据挖掘方法,通过可视化的知识图谱将语体相关核心关键词之间的隐性关系显性化,由此探讨十年来我国语体研究的热点和趋势。研究发现,十年来国内语体研究聚焦于本体研究和应用分析两方面以及语体理论、语体类型、语体研究方法、语体语法和语体教学五个方向。本文认为,语体研究将朝着更为精细化、专门化和系统化的方向发展,整体研究格局趋于平衡,研究方法与跨学科交叉研究参与度等方面也将得以丰富与提升。
[中图分类号]H052;H152 [文献标识码]A [文章编号]1674-8174(2024)01-0085-11
1. 引言
语体研究关注不同交际领域的语言变体及其语言运用规律,涉及语言手段分化、话语分类、言语行为以及话语建构与理解等方面,在言语交际中的地位举足轻重,成为学术界与社会关注的热点之一。在现代语言学的研究中,语体不仅是重要的研究视角,也是一种日趋成熟的语言描写与分析工具(姚双云,2017:3),当前西方的语体研究超越传统的基于语言形式与功能的分类体式,主要沿着三条路径开展研究:1)交际情境对语体的影响以及不同情境下语体使用特点和选择策略,如不同的交际场合人们使用的语言受交流意图、情感态度、社会地位等多元因素制约,相应的语体也会随之发生变化(Martin, 2009; Hasan et al., 2007; Butt & Wegener,2007; Eckert, 2000;Kiesling, 2005)。2)多模态话语分析下的语体研究,如Bernard & Mills(2000)探讨了布局、字体风格和显示格式等视觉因素对阅读理解的影响,并分析如何利用这些因素以更好地呈现和传达口头语体的信息。Hagoort et al.(2009)探讨了声音和视觉信息在语体感知中的协同作用,提出了声学和视觉特征在人类理解语言时相互作用的机制;Knoeferle (2015)则通过眼动追踪与事件相关电位(ERP)分析认为,视觉等非语言语境对口语词汇语义的构成与理解具有重要影响。3)数据驱动的语体分析,通过建立语料库数据,利用机器学习、统计学和自然语言处理等技术来研究语体变异和风格特征,探究其背后的规律和特点。比如语体在不同领域、年龄段和教育水平的群体之间会产生变异,通过机器学习的方法来识别和区分这些语体,从而深入探究它们的内在规律(Luzon Marco,2000;Bernardini,2002; Ghadessy et al., 2001; Hyland,2001);运用数据驱动的研究方法考察语体教学相关问题,即教师利用自然语言处理与机器学习技术,对学生的语言学习情况进行个性化分析和评估,从而更好地帮助学生提高语言技能(Gavioli,2002;Granger,2009;Biber et al.,2011)。数据驱动的方法为语体研究提供了一种基于实证分析的有效手段,具有广泛的应用前景,在增强语体研究的广度与深度的基础上,能够帮助研究者更为深入地把握不同交际领域下的语体变异方式和内在规律。
汉语学界的语体研究始于20世纪50年代,至八九十年代渐至深化并初步繁荣,成果数量不断增加且内容更为具体深入,如关注不同语体类型词句语篇的结构形式与语义特征(管琰琰,2014;赵宗飒、姚双云,2016)、语用功能(李秉震,2016;梁清沁,2022)以及汉语语体教学(曾毅平,2012;崔嵘等,2018),等等。为了更加深入清晰地呈现十年来国内语体研究现状与热点趋势,基于绝大多数规律的解释需要有形的科学计量结果的认知,本文采用数据驱动的语体研究路径,从2013—2022年CNKI中文学术期刊数据库中语体研究文献的关键词切入,依次通过词频统计、相异系数矩阵分析、系统聚类分析与多维尺度分析等方法探究汉语语体研究的热点主题、演进特征与发展趋势。
2. 研究数据与分析框架
2.1 数据来源、采集及处理程序
本文将CNKI中文学术期刊数据库中有关语体的研究论文作为数据来源,数据采集及处理程序为:1)以“语体”作为检索主题词,年限设为2013—2022年,检索出相关论文1972篇;2)对检索出的文献展开数据清洗,筛选出1905篇有效文献作为数据源;3)依次导出1905篇论文的信息,规范数据编码格式,使其符合研究处理要求。
2.2 分析框架
本文通过数据挖掘以及知识发现等技术将隐性知识显性化,进一步透视该知识体系中的现状与热点,预测语体研究的发展趋势。运用BICOMB对1905篇文献进行关键词提取统计与分析,经过标准化处理后,对频次出现15次及以上的前35个高频关键词进行统计分析,并建立主要关键词的词篇矩阵和共现矩阵。应用Ochiai系数分析法进行相异矩阵分析、系统聚类分析和多维尺度分析,深入探究语体研究热点与趋势的领域分布。
3. 研究结果与讨论
3.1 语体研究概况
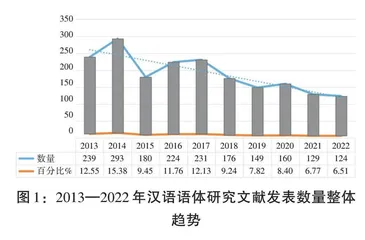
对国内2013—2022年语体研究的相关文献进行历时统计(见图1)可知,十年来我国语体研究有较多波动,文献数量整体上呈现波浪式小幅递减趋势。
2013—2014年有关语体研究的文献发表量整体增长,随后语体研究热度有所减退,2015—2017年的发文量与前一阶段相比稍有下降,但整体仍呈增长态势,2018—2022年语体研究的成果数量呈下滑趋势。本文认为,该趋势出现的主要原因是受学科发展规律的制约,当前我国语体研究已有六十余年的发展历程,语体的本体研究和应用分析显著增强,随着语体理论的适用范围不断向外拓展,语体研究释放出更强的吸引力和解释力,在其发展成熟之后的研究热度会出现暂时性消退。通过分析发现,2018—2022年阶段的语体研究虽然有所退热,但研究进程并未停止不前甚至迎来新的转向,语体研究的视角与内容更为具化深入多元,理论框架与方法更为丰富,研究视野也越来越多地呈现出跨学科交流与融合的趋势,语体研究与功能语言学、语篇语言学、计算语言学、翻译学、批评话语分析、认知语言学以及社会历史文化等学科领域的结合更加紧密,涌现出一批有价值的研究成果,如柳晓辉(2015)考察了语体学中蕴含的认知语言观;祝克懿(2020)从交际需求出发分析了“语录体”的源起与“记录”“摘录”互文手段的实现路径,描写解释了古今语录体分化融合的外部条件和内在理据;赵芃(2021)从批评话语分析的语体链分析视角分析语体变异现象。另外也有不少研究融合运用语料库技术与统计学方法(如单因素协方差分析、多元回归、皮尔逊相关检验、卡方检验、t检验等)对不同语体进行量化分析(如赵雪、 李平, 2013; 庞双子, 2019, 2020;胡俊飞、陶红印,2017;刘艳春,2019;胡显耀等,2021),这种研究路径具有数据量大、真实性高、覆盖面宽、时间跨度广、分析方式多样等优势,能够对语体的细微特征进行多角度、全方位的分析。
3.2 词频统计分析
为深入分析十年来语体研究的现状和热点,运用BICOMB对筛选出来的1905篇文献进行关键词提取统计与分析,并对关键词提取进行标准化处理,即合并同义表述的关键词使统计结果更为准确(如表1)。结果显示,2013-2022年的学术期刊论文共提取出关键词5281个,所有关键词累计出现总频次为8815次,本文提取出现频次15次及以上的关键词共35个,出现频次占关键词总频次的17.47%,按照出现频次的高低排序,依次为:语体、语体特征、语料库、翻译、口语语体、书面语体、网络语言、新闻语体、修辞、语境、翻译策略、语体风格、文体、语域、语义、科技语体、互动研究、同义词、语用、句法、语言、词汇、对外汉语教学、主观性、语体语法、特征、修辞学、语言特征、多维度分析、语体色彩、语体学、语体研究、风格、计量分析、语法。
上表在一定程度上反映了汉语学界围绕“语体”这一主题词展开的研究方向,体现了十年来语体研究的主要领域。表1数据初步表明,语体研究的视角和方法是多元的、跨学科式的,它与文体、修辞、语境、语法、翻译、互动等概念关系较为密切。然而仅凭词频统计并不足以准确描述语体研究的热点和发展脉络,因此在确定高频关键词后进一步对数据进行挖掘,通过对35个高频关键词进行共词分析和相似性分析,得到关键词的相异系数矩阵。
3.3 相异系数矩阵分析
使用BICOMB对35个高频关键词进行共词分析,生成词篇矩阵,选取Ochiai系数将该矩阵转化为共词相似矩阵,再采用相异系数矩阵=1-相似矩阵的运算,生成相异系数矩阵,用以说明主题词“语体”与其他核心关键词之间的关系。出于篇幅考虑,本文截取关键词排名前15的相异矩阵以作说明,具体见表2。
相异系数是显现两个变量间距离的统计变量,常介于0和1之间,矩阵中的数值表示关键词之间的相异性,各数值的大小表明各关键词之间的亲疏关系:相异系数越小,表明两关键词间的距离越近,相似度越大,密切程度越高;当相异系数趋于0时,说明两关键词间的关系最为密切。相异系数越大,说明两关键词间的距离越近,相似度越小,关系越疏远;当相异系数趋于1时,说明两关键词之间的关系最为疏远。由表2可知,各核心关键词距离主题词“语体”的顺序由近及远依次为:语境(0.850)、语体风格(0.896)、修辞(0.904)、语域(0.924)、语料库(0.939)、书面语体(0.957)、翻译(0.961)、网络语言(0.963)、语体特征(0.972)、口语语体(0.972)、新闻语体(0.976)、文体(0.979)、语言特点(0.980)、翻译策略(0.991)。通过分析35个高频关键词之间的相异系数发现:主题词“语体”和其他高频关键词之间,以及各关键词之间联系相对密切,但这些关键词在语体研究领域中的发展空间还较大,需要进行更进一步的探索;语体与修辞、文体等概念联系紧密;语体与语境、语体风格、语体特征以及具体语体类型(如书面语体、口语语体、新闻语体等)息息相关。关键词“语域”“翻译策略”“语言特点”与其他关键词的联系较为疏远,这表明对“语域”“翻译策略”“语言特点”与其他关键词的交叉领域研究仍具有较大发展潜力,需要进一步研究探索。
3.4 系统聚类分析
在上述相异系数矩阵分析的基础上进行系统聚类分析,可以更加清晰地聚合呈现关键词“语体”与其他核心关键词以及关键词之间的亲疏关系。为了清楚呈现十年来国内语体研究的不同领域和层次,本文充分利用共词分析与相似性分析结果,对35个高频关键词进行系统聚类分析,得到语体研究的高频关键词系统聚类树状图,然后根据聚类分析结果图显示类团的连线距离远近,将关键词聚合为五个主题领域(见图2),系统聚类分析将相异系数矩阵中核心关键词之间的隐性关系更加明晰地呈现出来。
通过分析表2可知,语体研究的五个主要方向分别为语体理论研究(包括语体、特征、翻译、语域、风格、语境、文体、互动研究、网络语言、主观性10个关键词)、语体类型与研究方法(包括口语语体、书面语体、语体特征、多维度分析、语料库、新闻语体、语言特征、翻译策略、科技语体9个关键词)、语体修辞(包括语体研究和修辞学2个关键词)、语体教学(包括词汇、语法、语体学、修辞、语言、计量分析、语体风格、对外汉语教学8个关键词)、语体语法(包括语义、句法、语用、同义词、语体色彩、语体语法6个关键词),通过聚类分析得出的这五个研究方向表征十年来国内语体研究的热点。
4. 语体研究的热点与趋势分析
对高频关键词的线性拟合散点(见图3)进行检测,结果显示,所有的实测值和预测值分布散点具有线性趋势,这说明该数据模型的拟合程度良好。在此基础上,本文基于上文的系统聚类分析结果做进一步进行多维尺度分析,并绘制出语体研究热点与趋势的知识图谱(见图4)。
在多维尺度知识图谱中,横轴表征向心度(Centrality),显示该领域的关键词相互影响的强度;纵轴表征密度(Density),呈现某领域内部的联系强度;图中的小圆点表征各关键词所处的位置,圆点间的距离越近,说明它们的关系就越密切;反之,则关系越疏远;关键词的影响力越大,其所标示的圆圈距离坐标的中心点越近。分析图4可知,所有的关键词分布在四个象限内,象限的不同体现着当前关键词在该领域所处的研究地位,关键词和主题词“语体”之间关系的亲疏程度,以及不同领域的动态研究信息。
根据语体研究的高频关键词聚类树状图(图2)和语体研究热点知识图谱(图4),按照相近性划分领域数量,依据各领域关键词的内容为该领域命名(若某类别下出现若干差异较大的关键词,则概括不同关键词所含的共同点,以共同点进行命名),将2013-2022年国内的语体研究总体上划为两方面、五个方向:一是本体研究,包括语体理论研究、语体类型研究与语体研究方法、语体语法研究;二是应用研究,包括语体教学研究等。多维尺度分析是在系统聚类分析的基础上的进一步具体细化,该分类与上文的高频关键词词频分布、系统聚类树状图的领域划分基本一致,这也说明以知识图谱的分析方法研究语体研究的热点与趋势问题具有客观性和科学性。