基于多模态表征的医学影像报告生成方法研究
作者: 郭继伟 鲁慧哲 许杰
摘要:医学影像报告自动生成需要关注影像的整体结构与局部细微变化以生成准确流畅的文本描述。为此,文章提出了基于多模态表征的医学影像报告自动生成方法,利用跨模态注意力机制和滑动窗口机制分别获得影像与报告之间的局部以及全局特征,通过门控融合机制,自适应整合来自不同尺度的多模态特征,在保持对影像全局感知的同时又能关注到微观变化。在IU X-Ray数据集的实验结果表明,文章所提出的方法在BLEU-2/3/4、ROUGE-L以及METEOR指标上领先于基线方法。
关键词:医学影像报告;多模态表征;多模态融合;跨模态注意力机制
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2025)08-0019-03
开放科学(资源服务) 标识码(OSID) :
0 引言
医学影像在临床诊断中扮演着重要的角色,为医生提供丰富的诊断信息。然而,解读医学影像高度依赖于医生的专业知识与临床经验,面对日益增长的影像数据,医生需要花费大量时间进行解读,增加了工作负担[1]。因此,医学影像报告生成(Medical Report Generation,MRG) 已经成为人工智能领域一个热门的研究方向。
目前,医学影像报告生成方法[2-3]多使用卷积神经网络提取影像特征信息,利用循环神经网络及其变种生成相应的报告。鉴于循环神经网络在生成文本时需要依赖先前隐藏状态,存在报告生成效率低,以及无法利用长距离交互等问题,影响生成报告质量。随着Transformer[4]在各项任务领域中展现出巨大的优越性,越来越多的研究人员开始关注基于Transformer架构的医学影像报告生成框架。Chen等[5]提出基于记忆驱动的Transformers医学影像报告生成模型。在生成过程中,利用关系存储器(RM) 记录关键信息,并利用存储器驱动的条件层规范化(MCLN) 将其整合到Transformer解码器中,从而生成内容丰富的长篇医学影像报告。为了探究影像与文本之间的映射关系,跨模态记忆网络(Cross-modal Memory Networks,CMN) [6]设计一个共享存储器来记录图像和文本之间的映射信息,用于促进跨模态交互和医学影像报告的生成。虽然在上述工作的驱动下,医学影像报告生成的质量得到显著提升,但在该领域仍存在一些挑战,医学影像报告需要关注影像整体与局部信息,帮助临床医生精准地评估患者健康状况。
本文提出基于多模态表征的医学影像报告生成方法,使用自适应注意力机制建立全局、局部影像特征与文本模态之间的交互信息,用于生成准确流畅的医学报告。在自适应注意力模块中,跨模态注意力机制构建全局多模态表征,滑动窗口机制构建局部多模态表征,门控融合机制自适应地融合来自不同尺度的多模态表征信息,这使得模型在保持对全局感知的同时又能关注到微观的变化,从而生成准确流畅的医学影像报告。本文在印第安纳大学公开的IU X-Ray数据集[7]上进行大量实验,在BLEU-2/3/4、ROUGE-L以及METEOR评价指标上优于基线。
1 模型概述
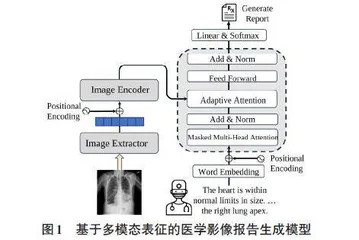
医学影像报告生成任务是从给定的医学影像I中提取关键信息,生成准确流畅的医学报告Y。图1展示本文提出的基于多模态表征的医学影像报告生成模型的整体架构,该模型包括视觉特征提取器、视觉特征编码器以及基于自适应注意力机制的解码器。
1.1 影像特征处理
本文使用预训练卷积神经网络ResNet[8]作为图像特征提取器(Image Extractor) 提取输入影像[I]的特征,影像按照网格分割的形式被分解为多个大小相等的区域(patch) ,[{x1,x2,...,xn}=fres(I)∈Rn×d] ,其中[n]代表patch数量,[d]代表patch的特征维度。将经过视觉特征提取器得到的patch特征加入位置编码(用于记录patch在原始图片中的位置信息) 后作为视觉编码器(Image Encoder) 输入,对于视觉编码器,本文采用的是标准的Transformer编码器,没有做任何改动,输出视觉编码器的隐藏状态,[H=fe(x1,x2,...,xn)∈Rn×dh],其中[n]代表patch的数量,[dh]代表隐藏状态维度,[fe]代表视觉编码器。
1.2 解码器
在基于多模态表征的医学影像报告生成模型中,解码器主要包括前馈神经网络(Feed Forward)、自适应注意力机制(Adaptive Attention)、有遮掩的多头注意力机制(Masked Multi-Head Attention) 以及残差连接和层归一化(Add & Norm) 。与传统的解码器不同之处在于,针对医学影像需要关注不同尺度的特征,本文引入自适应注意力机制,通过自适应门控机制,动态融合来自全局与局部两种不同尺度的多模态表征信息,用于生成准确流畅的医学报告。
自适应注意力机制接受源序列和目标序列作为输入,其中源序列是来自视觉编码器输出[H],目标序列是医学影像报告经过有遮掩的多头注意力机制及残差连接和层归一化的输出[Y']。在整个多模态序列内,利用跨模态注意力机制,获得全局多模态表征信息,具体公式描述如下:
[Ma=CoAttentionH,Y' =softmaxY'WQaW⊤KaH⊤dhHWVa] (1)
式中:[Ma]代表全局多模态表征信息,[WQa]、[WKa]和[WVa]是可训练的权重矩阵,[dh]是来自视觉编码器输出的特征维度。通过滑动注意力窗口机制,将参与交互的多模态数据限制在给定窗口大小范围内,从而获得局部的多模态表征信息,假设给定窗口半径为[w],对于任意位置[i],只允许关注到[Win i=[max(0,i-w),min(i+w,n)]]内的信息。具体公式描述如下:
[Attention_mask(i,j)=0, if j∈ Win (i)-∞, otherwise ] (2)
[Ml= SWAttention H,Y' =softmaxY'WQlW⊤KlH⊤dh+Attention_maskHWVl] (3)
式中:[Ml]代表局部多模态表征信息,[WQl]、[WKl]和[WVl]是可训练的权重矩阵。为融合来自不同尺度的多模态表征,使用门控机制,自适应地整合来自不同尺度的多模态表征信息:
[M=Ga(Ma)+Gl(Ml)=MaWTa+MlWTl] (4)
式中:[M]代表融合后得到的多模态表征信息,[Gl(⋅)]和[Ga(⋅)]代表门机制,[Wa]和[Wl]是可训练的权重矩阵。最后,解码器输出的信息经过一个线性层映射到字典维度,使用Softmax函数计算输出的概率分布。
2 实验设置
本小节首先介绍模型的评价指标,然后对实验结果进行分析。
2.1 实验评价指标
本文使用自然语言生成领域常用的评价指标来评估基于多模态表征的医学影像报告生成模型结果与真实报告之间的精确率,包括以下指标:
BLEU-[n]指标:双语互译质量评估辅助工具[9](n代表连续文本的个数,通常包括BLEU-1/2/3/4) 。BLEU-1可以衡量生成报告和真实报告在单词级别的一致性,对于BLEU-2/3/4可以衡量两者的流畅度。BLEU-n分数越高,表示模型性能越接近于人类表现。
ROUGE指标:ROUGE[10]是一种侧重召回率的评价指标。ROUGE-L作为ROUGE的一种重要变体,使用最长公共子序列作为匹配基础,能够更加灵活地捕捉生成文本与真实文本之间的相似性,ROUGE-L分数越高代表模型表现效果越好。
METEOR指标:与BLEU和ROUGE不同的是,METEOR[11]指标是基于整个语料库上的准确率和召回率,引入多层次匹配机制,不仅考虑精准匹配还包括同义词匹配、词干匹配等,更加符合人工判别的标准。METEOR分数越高,模型表现效果更好。
2.2 实验结果分析
本文所提出的模型在IU X-Ray数据集上进行了大量实验,与先前具有代表性的工作进行对比。具体有:通过记忆驱动的Transformer生成放射报告(R2Gen) [5]、用于生成放射报告的跨模态记忆网络(CMN) [6]以及基于图引导混合特征一致性的半监督医学影像报告生成(RAMT) [12]。
本文所提出的基于多模态表征的医学影像报告生成模型与R2Gen、CMN以及RAMT的实验结果对比(见表1) ,最优结果加粗展示。从表1中可以观察到,本文提出的模型在BLEU-2/3/4、ROUGE-L以及METEOR五项评价指标上都显著优于对比的基线模型,对于BLEU-1指标,本文所提出的模型表现略低于RAMT。本文所提出的方法相较于其他基线最优表现的对比结果如下:BLEU-2提升约为2.6%,BLEU-3提升约为3.6%,BLEU-4提升约为2.9%,ROUGE-L提升约为4.6%,METEOR提升约为2.1%,BLEU-1下降约为0.6%。针对不同场景,本文提出的模型可以动态地调整全局以及局部特征权重,兼顾影像的整体架构以及细节,实现在医学影像报告生成领域的先进性能。
3 总结与展望
本文提出基于多模态表征的医学影像报告生成模型,利用门控融合机制,自适应地融合来自不同尺度的多模态特征,用于生成准确流畅的医学影像报告。在公开的IU X-Ray数据集上进行大量实验,与具有代表性的基线模型进行对比,实验结果证明文章中所提出的方法在医学影像报告生成领域的先进性。
尽管本文所提出的模型在医学影像报告生成任务中取得优异的性能,但也存在一些不足之处,主要体现在模型可训练的参数量庞大,未来将尝试剪枝以及知识蒸馏等方法探索轻量级的医学影像报告生成模型。
参考文献:
[1] 邢素霞,方俊泽,鞠子涵,等.基于记忆驱动的多模态医学影像报告自动生成研究[J].生物医学工程学杂志,2024,41(1):60-69.
[2] JING B Y,XIE P T,XING E P.On the automatic generation of medical imaging reports[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).Melbourne:ACL,2018:2577-2586.
[3] YANG Y,YU J,ZHANG J,et al.Joint embedding of deep visual and semantic features for medical image report generation[J].IEEE Transactions on Multimedia,2021,25:167-178.
[4] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems 30.Long Beach:NIPS,2017.
[5] CHEN Z,SONG Y,CHANG T H,et al.Generating radiology reports via memory-driven transformer[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.Online:EMNLP,2020:1439-1449.