韵律模式和语素位置概率对汉语学习者切分歧义词的影响
作者: 鹿士义 黄韵
[关键词] 词语切分;韵律模式;语素位置概率;基本加工单位
[摘 要] 在中文文本阅读过程中,读者如何对词语进行分词和识别,基本加工单位是什么,一直存在着争论。本文采用线上词汇命名任务,以汉语母语者和高级水平的二语者为被试,研究韵律模式和语素位置概率对汉语词语切分和识别的影响,并在此基础上探讨基本加工单位的大小问题。研究发现:韵律因素和语素位置概率显著影响词语的切分和识别;汉语母语者和二语者最大的差异在于二语者加工单位的长度小于母语者,这可能是由于二语者的知觉广度范围较窄导致的。汉语的基本加工单位大小基本遵循“长词优先”原则,同时受韵律特征、语素特征、语言水平等因素的影响。
[中图分类号]H195.3 [文献标识码]A [文章编号]1674-8174(2023)01-0043-09
1. 引言
由于汉语的书写系统缺乏词间空格,词边界不清晰,词语的识别与切分会导致以下三种情况:一、词语的识别和切分是同时进行的,是统一的过程(Li等,2009);二、由于缺乏词间空格等低水平视觉信息,需要更多地运用高水平的语言特征进行词语切分和识别;三、在汉语文本中,汉字比词更加突显。在汉语的基本加工单位这个问题上,学界暂未形成一致看法。因此,本文暂且跳过加工单位是什么的问题,从加工单位的大小切入,探讨汉语词语切分和识别过程会受到哪些高水平的语言特征的影响。
关于汉语基本加工单位的大小问题,目前已有的模型均预测更大的词汇单位更容易被识别出来,即长词优先(Inhoff et al,2005;Li et al,2009)。在知觉广度范围内,长词(如ABC)优先被选择和识别,内嵌词(即AB)的激活程度较弱。也就是说,人们更加倾向于切分出较大的单位作为基本加工单位。
Zhou等(2018)采用了长度为三个字符的组合型歧义材料进行实验,如“艺术家”,发现内嵌词(艺术)先于整词(艺术家)激活。这一结果可能表明,即使存在长词(多于两音节的词汇),读者可能仍会将两音节相结合并首先激活和识别,不一定存在长词优先激活的现象。相应地,Perfetti等(1999)则提出另一种预测——汉语母语者在阅读时会采用“二字结合策略”,加工单位的大小默认为两个音节的长度。“二字结合策略”得到来自于韵律的支持。冯胜利(2002:78)认为双音节音步是汉语最基本的“标准音步”,双音节化是现代汉语的主要节奏倾向(周有光,1961)。因此,“二字结合策略”是具有理论基础的。
值得注意的是,“二字结合策略”采用的实验材料是长度为三字符、链长为1的歧义字符串,如“照顾客”,因为ABC不成词,在切分上仅存在两字结合的可能性。因此,虽然不能否认“二字结合”策略的运用,但也同样不能否认,只要条件允许,也可能做出三字、四字结合的切分选择。Zang等(2015)的研究结果和“二字结合策略”的预测不一致。当语素A独立成词时,读者更少地把A和其右侧的B结合在一起加工。这意味着二字结合策略的运用会受到语素特性的调节。在一定条件下,汉语的基本加工单位可能小于两个音节。
总的来说,在现有的实验中,歧义字符串长度较小,切分可能性不多,不能很好地验证汉语基本加工单位的大小问题。而出现不同研究结论相左的情况,可能是由于影响加工单位大小的因素尚未厘清,如上文提到的韵律因素和语素特征信息。因此,为了更好地探究汉语基本加工单位的大小及其影响因素,本文拟以歧义字符串ABC和ABCD为材料进行实验,其中AB成词,ABC亦成词,后者CD亦成词。这一类型的歧义字符串存在多种切分的可能性,切分后单位大小不一,能够更充分地考察汉语词语的识别和切分以及切分后加工单位的大小。
2. 影响因素
影响词语切分和识别的因素众多,主要分为低水平视觉信息和高水平语言因素等,前者包括词间空格、词长等,后者包括词频、熟悉度、可预测性等。但本文主要关注韵律信息和语素特征,因为这两个因素关系着“二字结合策略”的应用,影响词语的识别和切分,从而影响基本加工单位的大小。
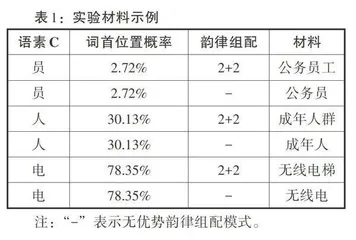
韵律(prosody),指的是语流中的超音段成分,在声学上表现为基频、时长、强度等(Wagner & Watson,2010)。在汉语中,双音节化是现代汉语的主要韵律节奏倾向(周有光, 1961),汉语韵律对单双音节的组合搭配有特殊要求。汉语的四音节序列绝大多数是按[2+2]这种节奏形式来切分直接成分的(Chao,1975)。四字字符串的自然韵律是[2+2](冯胜利,2002:101)。[2+2]的韵律组配模式可能影响汉语母语者的词语识别和切分,但汉语学习者是否习得[2+2]的韵律模式,并利用这一模式进行词语的识别和切分还有待进一步探讨。
语素特征同样影响汉语阅读中词汇识别和切分。在众多的语素特征中,位置概率在词语识别和切分中有着非常重要的作用(Kasisopa 等,2013、2016;Sainio等,2007;Yen等,2012;Liang等,2017;高淇,2018)。在以汉语二语者为对象的研究中,同样发现语素位置对其词汇的识别和切分造成影响(洪炜等, 2010; 陈琳等, 2016; 邢滨钰等, 2018)。但是,语素位置概率对汉语二语者词汇识别或切分影响的研究目前还很少见到。因此,本研究拟操纵语素位于不同位置的概率大小,探究其对汉语学习者词语加工的影响。
本研究拟以歧义词组ABC和ABCD为实验材料,采用线上词汇命名任务,探讨二语者能否利用韵律信息和语素位置概率信息进行词语识别和切分,从而探究汉语加工单位的大小问题。其中,韵律信息具体指[2+2]组配模式,语素位置概率指的是一个语素在词中位于词首或词尾的概率。研究的具体问题如下:
第一,汉语学习者是否受韵律模式的影响,将歧义四字字符串ABCD按照[2+2]的组配模式进行加工,切分出较小的单位——双音节词语,而非“长词”三音节词语?而未有优势韵律模式的歧义词语ABC会出现怎样的切分结果呢?两类歧义词语的切分结果是否不同?
第二,汉语学习者在加工字符串ABC和ABCD时,C的语素位置概率是否会影响切分结果?即,学习者是否会根据C位于词首或词尾的位置概率高低,做出不同的切分呢?
3. 实证研究
3.1 实验设计
本实验采用三因素混合设计。三因素分别为:(1)母语背景:汉语母语者和母语非汉语的二语者;(2)歧义字符串ABC和ABCD中第三个字符C的语素位置概率;(3)歧义字符串的韵律组配模式:字符串ABCD存在[2+2]优势韵律模式,而ABC缺乏优势韵律模式。其中母语背景为被试间因素,后两者为被试内因素。
本实验采用词汇命名任务,要求被试在字符串呈现后快速报告第一个看到的包含在歧义字符串的词语,因变量为被试所报告的双音节词或三音节词的情况。
3.2 被试
被试为汉语母语者和汉语二语者各18名。其中,汉语母语者被试中,男、女各9人,均为在校学生;二语被试中,男7人,女11人,平均年龄为25岁,HSK等级为五级到六级,汉语学习的平均时长为6.1年。
3.3 实验材料
本实验以歧义字符串ABC和ABCD为实验材料。从《汉语水平词汇与汉字等级大纲》挑选AB且ABC成词的词语,并根据C挑选词语CD。所选取的词语大多属于甲级词或乙级词。邀请未参与实验的高级水平汉语学习者15名,采用4点量表对歧义词组中所包含的词AB、ABC、CD进行熟悉度评定。共得到32组歧义词组ABCD和32组歧义词组ABC,熟悉度平均值为3.60。
词AB的平均词频约为6.62万 (SD = 1.07),词ABC的平均词频为5.56万 (SD = 0.83),词CD的词频为7.63万(SD = 1.88)。方差分析表明,三者的平均词频没有显著差异,F(2,93) = 0.195 (p > 0.05),事后分析表明,词AB和词ABC之间(p = 0.752 > 0.05)、词AB和词CD(p = 0.759 > 0.05)、 词ABC和词CD (p = 0.534 > 0.05)之间均没有显著差异。
词AB的平均笔画数为6.569(SD = 1.84),词ABC的平均笔画数为6.64(SD = 1.73),词CD的平均笔画数为6.88(SD = 2.12)。方差分析表明,三者的平均笔画数不存在显著性差异,F(2,93) = 0.236,p > 0.05),词AB和词ABC(p = 0.878 > 0,05)、词AB和词CD(p = 0.513 > 0.05)、词ABC和词CD(p = 0.616 > 0.05)之间均没有显著差异。
在两类歧义字符串中,第三个汉字C作为词首或词尾的位置概率在BCC语料库《汉语常用词词频表》(荀恩东等,2016)中计算。C位于词首的位置概率P (CI)等于C位于词首的词数除以首尾包含语素C的所有词数(Yen et al,2012),公式为:P(CI) = N(Cinitial) / N(Cinitial + Cending) ×100%。同理,C位于词尾的位置概率P (CE) 计算公式为: P (CE) = N(Cending)/N(Cinitial+Cending)×100%或P(CE) = 100%-N(Cinitial)/N(Cinitial+Cending) × 100%。
本实验材料中,汉字C位于词首的概率范围为2.72%至78.35%,平均值为30.92%(SD = 15.09)。
将64组材料分为两个版本,每个版本32组材料。每个版本中,同一个语素C所对应的歧义字符串的韵律组配模式只出现一次,即被试只阅读ABCD和其对应的ABC中的其中一个。另外加入2倍左右的填充词组,共58组。每个版本的实验材料和填充材料经过完全随机排列后分为3个板块,每个板块包含30组词语。另外挑选包含上述所有类型的词组34组,随机分为两个部分,作为练习阶段的材料。
3.4 实验仪器与程序
本文采用线上视频形式进行实验,使用E-prime 2.0软件编程,通过Bandicam软件将其录制成视频。主试将2个练习视频和3个正式实验视频发送给被试,被试在电脑上全屏播放,进行实验。实验参考Ma等 (2014) 的模糊词报告范式。
首先呈现注视点“+”500ms,接着呈现500ms的空屏,然后快速呈现歧义词组。之后出现一个持续3000ms的空屏,要求被试在空屏出现时又快又准确地报告第一个看到的包含在歧义词组中的词语。3000ms之后出现下一次注视点“+”。通过前测,确定汉语母语者实验时歧义词组的呈现时间为100ms,汉语二语者为600ms。视频实验结束后,汉语二语者被试需要填写两份调查问卷,分别是交际语言能力自评表和实验材料的熟悉度评定问卷,而汉语母语者仅需要完成后者。整个实验大约持续30分钟。
4. 实验结果与分析
词语命名的具体情况见表2。删去命名错误的数据50条,占全部数据的4.34%,有效数据为1102条。
实验数据在R语言(version 3.6.3)软件上分析。本实验的因变量为5个水平的类别变量,分别为单音节词、双音节词、三音节词、先二后三、先二后加一,原始数据及调整后数据均不符合正态分布,且程度上无先后顺序分布,因此本研究利用nnet数据包(version 7.3-13)中的multinom函数,即采用无序多分类logistic回归模型,分析实验数据。
本研究关注的解释变量为:被试的语言背景(母语者、汉语二语者,编码为group0和group1)、韵律组配模式(有/无优势韵律模式,即字符串ABCD和ABC,编码为type4和type3)、语素C位于词首的位置概率(编码为LP)。本文的结果变量为词汇命名情况。在对数据进行编码和整理后,采用最大似然法(Maximum Likelihood Technique)建模。最优模型包含母语背景、韵律组配模式和词首位置概率的固定效应,以及韵律和位置概率的交互效应,统计输出结果如表3所示。