基于认知诊断理论的国际中文阅读测验Q矩阵的构建
作者: 刘慧 李亚男
[关键词] 认知诊断;阅读测验;Q矩阵
[摘 要] Q矩阵的合理构建是成功进行认知诊断分析的先决条件,然而对目前广泛存在的非诊断性大型标准化测验来说,确定Q矩阵是一项极具挑战性的工作,国际中文阅读测验也不例外。本研究以YCT(四级)阅读测验为例对大型标准化国际中文阅读测验Q矩阵的构建进行探讨。研究通过文献回顾和专家判断得到了测验所考查的子技能并初步构建Q矩阵,然后基于R-RUM模型的分析结果从量化角度对初始Q矩阵进行优化并检验。结果表明,YCT(四级)阅读测验考查了“词汇识别”“句法分析”“语义命题构建”“推理”四种子技能;通过质性分析和量化分析相结合的方法可以有效构建国际中文阅读测验Q矩阵,从而为后续的诊断分析打下良好的基础。
[中图分类号]H195.6 [文献标识码]A [文章编号]1674-8174(2023)04-0068-09
[收稿日期] 2022-08-16
[作者简介] 刘慧,女,北京语言大学语言科学院助理研究员,博士,主要研究方向为语言测量、教育测量。
电子邮箱:[email protected]。 李亚男,女,北京语言大学语言科学院在读博士,汉考国际总经理助理兼研发总监,主要研究方向为语言测试、国际中文教育。电子邮箱:[email protected]。
[基金项目] 国家语委科研项目“国际中文阅读测验认知诊断信息挖掘研究”(YB145-14);汉考国际科研基
金项目“基于出声思维的HSK(四级)阅读测验认知结构研究”(CTI2021B03);北京语言大学院级项目(中央高校基本科研业务费专项资金)“汉语作为第二语言测验认知诊断分析的效度研究”(22YJ170001)
1. 引言
阅读能力是人类最重要的能力之一,同时,阅读能力高度复杂。尽管在阅读能力的构成上,以往研究者并未能完全达成一致,但绝大多数研究者认为阅读能力由不同能力要素构成(Lee & Schallert,1997)。在语言测验领域,很多研究者认为阅读能力是可细分的(Grabe,2009:39),这些细分的阅读能力就称为阅读子技能。
在国际中文教育中,学习者阅读能力的发展情况,是教学中师生共同关心的问题。现实中,由于个体差异的存在,尤其是国际中文学习者背景(母语、性格、语言学习能力、学习风格、动机、对语言学习的态度等)差别大,这会在不同程度上对国际中文习得的不同方面产生影响,其阅读能力的发展情况也会更加分化。然而,对于各阅读子技能发展情况的描述,传统的测验分数和偏误分析都无法实现,而认知诊断分析可以胜任。
认知诊断理论通过运用统计模型识别技术,能够从被试在测验各个题目上的实际作答反应出发,推断其内在子技能的发展状况。阅读领域的认知诊断分析可以报告学生各阅读子技能发展情况,明确其优势和弱势;能够为下一步的教学提供更加详细的建议,进行更加直接的指导,为“因材施教”提供基础。
实际上,语言测验都有提供诊断信息的潜力(Bachman,1990:60),以往国内外相关研究也确实在阅读领域成功进行了一系列诊断分析(Buck、Tatsuoka & Kostin,1997;Jang,2009)。不过,纵观以往阅读测验领域的诊断研究,尤其是国际中文阅读的相关研究,关注点多在于认知诊断模型的使用,主要考查认知诊断模型能否应用于相应的测验,而对于如何构建Q矩阵关注不足。
Q矩阵反应的是子技能水平上的测验结构,其合理构建是成功进行认知诊断分析的先决条件(Tatsuoka,1983)。同时,目前的阅读测评使用的几乎均为大型标准化测验,这些测验一般基于非诊断目的开发,属于传统的非诊断性测验;想要从中获取诊断信息,更是需要首先分析测验本身所考查特质的构成,确定Q矩阵。因此,研究拟以中小学生汉语考试(以下简称“YCT” )测验为例,对国际中文阅读测验Q矩阵的构建进行专门探讨,具体研究两个问题:(1)YCT(四级)阅读测验考查了哪些阅读子技能?(2)国际中文阅读测验的Q矩阵应当如何构建?期望对上述问题所进行的探讨,能够为后续研究确定Q矩阵提供更多参考建议,提升国际中文阅读测验诊断分析的效用。
2. 研究背景
2.1 认知诊断理论
认知诊断理论(Cognitive Diagnostic Theory,CDT)是新一代测量理论,它不将测量的特质看作意义模糊的统计结构,而是致力于描述个体不同的认知结构。认知诊断理论由Q矩阵和认知诊断模型两部分构成。
Q矩阵定义的是正确作答每道题目所需要掌握的子技能,它从不可观测的多个潜在子技能的角度对可观测的测验题目的表现进行解释,体现了子技能水平上的测验认知结构。Q矩阵的行代表题目,列代表子技能;如果Q矩阵的元素qjk的值为1,就表示第j道题目考查了第k个子技能;如果为0,就表示第j道题目没有考查第k个子技能。
认知诊断模型根据Q矩阵和实测作答反应来推断被试子技能掌握状态,目前大多数认知诊断模型都定义了一个函数,这个函数用来表达被试对某道题目正确作答的概率与这道题目所考查的子技能和被试的子技能掌握情况之间的关系;它们既可以用于专门的诊断性测验,也可以用于传统的非诊断性测验(Fu & Li,2007)。
2.2 以往的阅读认知诊断研究及其Q矩阵的构建
从上世纪末开始,研究者就已经开始了阅读领域的认知诊断研究,目前已经有了一定的积累。以往研究中,绝大多数都是基于传统的非诊断性测验开展的。
Buck等(1997)是阅读领域首批认知诊断研究的代表,研究采用文献回顾、专家判断和回归分析等多种方法确定Q矩阵,然后使用规则空间模型对考生在托业考试阅读部分的作答进行分析。Jang(2009)是后期研究的代表,研究采用文献回顾、出声思维和基于缩减融合模型(The reduced reparametrized unified model,R-RUM)的量化分析方法确定Q矩阵,并用R-RUM对LanguEdgeTM阅读测验进行认知诊断分析。蔡艳等(2011)是国内相关研究的代表,研究采用文献回顾和专家判断方法建立Q矩阵,并采用分层回归分析等方法对Q矩阵进行认定,然后使用属性层级模型对英语高考阅读理解进行分析。
在国际中文阅读领域,也有研究者不断进行探索。黄海峰(2010)采用文献回顾和因素分析相结合的方法确定了Q矩阵,然后使用融合模型对考生在汉语水平考试(HSK)初、中等阅读测验上的作答表现进行分析;鹿士义和苗芳馨(2014)采用文献回顾和问卷调查相结合的方法确定子技能及其层级关系并计算Q矩阵,然后使用规则空间模型对某大学入学分班的阅读理解测验进行诊断性研究。
由以上研究可知,Q矩阵的构建是进行诊断分析的重要基础。Q矩阵构建通常通过“定义子技能”和“建立Q矩阵”这两个步骤实现(Lee & Sawaki,2009)。“定义子技能”时,一般会对相关领域认知子技能构成的理论进行回顾,并结合目标测验的特点对测验所考查的子技能进行定义;在条件具备的情况下,出声思维法和专家判断法也是定义子技能的比较有效的方法。“建立Q矩阵”时,一般会使用两类方法,一类是仅基于对测验内容本身的分析,另一类是将测验内容分析和量化分析相结合。第一类方法是指由一位或者多位专家对目标测验的每道题目内容进行分析并编码(Douglas、de la Torre、Chang、Henson & Templin,2006),第二类方法是指在测验内容分析的基础上,再依靠量化分析识别内容分析中专家判断与实测数据不匹配之处,进而对依据测验内容分析所建立的Q矩阵进行优化。
以往大多数阅读认知诊断研究在建立Q矩阵时,采用了将测验内容分析和量化的实证数据分析相结合的方法。在量化方法的选择上,有研究采用了因素分析(Jang,2005;黄海峰,2010)、回归分析(Buck等,1997)等方法,也有研究采用了基于认知诊断模型的量化分析方法。这些方法中,因素分析方法表现并不太好,尤其是对于传统的非诊断性测验来说(Li & Suen,2014);回归分析方法也只能对Q矩阵的合理性进行较为粗略的判断;而不少认知诊断模型能够对单个测验题目的表现进行分析,并能够对子技能分配的具体情况进行评估,从而更精确地识别测验内容分析中可能出现的误判,在Q矩阵构建中表现良好。R-RUM模型 (DiBello、Stout & Roussos,1995)就是这种认知诊断模型的典型代表。
在国际中文阅读测验领域,以往诊断研究在构建Q矩阵时,仅仅通过测验内容分析直接确定Q矩阵(鹿士义、苗芳馨,2014),或者在测验内容分析的基础上,通过因素分析、回归分析等量化分析对Q矩阵的合理性进行总体评估(黄海峰,2010);少有研究采用基于认知诊断模型的方法对Q矩阵的合理性进行精细评估。
3. 研究方法
3.1 研究工具
本研究所用测验为YCT(四级)的阅读分测验。
YCT是一项旨在考察汉语非第一语言的中小学生的汉语应用能力的大型国际汉语能力标准化考试,分为四个级别,水平从低到高分别为YCT(一级)、YCT(二级)、YCT(三级)、YCT(四级)。YCT(四级)考查考生的日常中文应用能力,共80题,分听力、阅读和书写三部分,其中阅读测验长度为30题,包括四种题型,均为四选一的单项选择题。第一种题型,每题提供一张图片和3个句子选项,要求考生选出对应图片的一项;第二个题型提供20个句子,每10个一组,要求考生找出对应关系;第三个题型提供一个单轮对话,对话中有一个空格,要求考生选词填空;第四个题型提供一句或两句话,之后有一个问题,要求考生从备选项中选出答案。
3.2 研究设计
研究拟综合采用文献回顾法、专家判断法和基于认知诊断模型的量化分析方法构建Q矩阵。首先,通过文献回顾法初步析出测验所考查的阅读子技能;然后,利用专家判断法,对初步析出的子技能进行考查并构建初始Q矩阵;接下来,采用基于R-RUM模型的量化方法对初步构建的Q矩阵进行优化;最后,对Q矩阵的合理性进行检验。
专家判断法的基本流程为:(1)对目标测验的目标群体、考察目的、测验构成等相关情况进行详细介绍,为专家分发全部题目,并请专家阅读试题;(2)介绍主要的阅读能力认知结构理论模型,报告初步析出的阅读子技能清单;(3)请专家结合目标测验具体情况,对初步析出的子技能清单进行讨论,确定子技能清单;(4)专家对目标测验的每一道题目独立标注目标群体在作答时需用到的子技能;(5)全部专家对题目标注完成后,对各题所考查的子技能进行逐题讨论;如果专家们在某题目上无法达成一致,就采用专家出声思维法对该题考查的子技能进行讨论并做出决定;(6)基于专家组确定的各题所考查的子技能,构建初始Q矩阵。
3.3 被试构成和专家组构成
3.3.1 被试构成
研究采用的数据为2017年4月全球施测的YCT(四级)阅读分测验的考生作答结果和成绩,经清理后的有效数据共1101条。试卷质量分析显示:以原始分计,考生成绩均值为18.04,测验的平均通过率为0.60,试卷难度中等偏易;全卷标准差为6.67,考生成绩变异合理,考生成绩全距为2分到满分30分,得分分布较广;试卷α系数为0.88,信度较高,较为稳定;全卷平均点二列相关为0.47,题目区分度很好,试题质量不错。
3.3.2 专家构成
专家组由5名成员构成,均有三年以上国际中文教学经验,熟悉汉语水平考试,且长期参与YCT或HSK的命题、审题工作。其中,有三位专家为大学教师,两位专家为考试机构资深工作人员,另有一位语言学专业的硕士生进行会议记录。
3.4 数据处理
研究过程中涉及到的数据处理有三类:基本测量学指标的分析采用ITEMAN软件完成,基于R-RUM进行的分析采用Arpeggio软件完成,其他的数据整理和处理采用R软件自编程序完成。
4. 研究结果
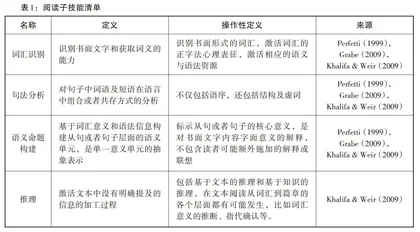
4.1 认知子技能的初步析出及确认
研究首先基于YCT(四级)阅读测验的基本特点,在阅读认知过程和阅读能力评估相关文献分析的基础上,初步析出了YCT(四级)阅读测验所考查的阅读子技能初始清单。