智驾惹祸,全怪算法?
作者: 陈惟杉 王诗涵
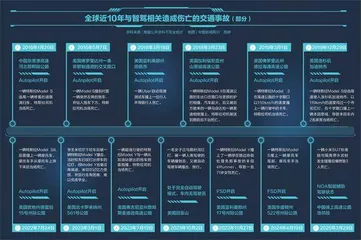
3月29日晚间,一辆小米SU7以116公里/小时的速度在高速路上行驶,路遇道路施工,车辆需要改道行驶,但因变道不及时最终以97公里/小时的速度与水泥护栏发生碰撞,车辆随后发生火灾,驾驶员和另外两名乘客不幸遇难。
碰撞发生前数秒,车辆处于NOA(辅助导航驾驶)状态。直到事故发生前两秒,NOA发出风险提示“请注意前方有障碍”,发出减速请求,并开始减速。下一秒,驾驶员接管,随后碰撞发生。这随即引发公众有关现阶段辅助驾驶系统感知能力、接管机制等一系列问题的追问。
系统报警到碰撞的4秒里,驾驶员仅有1.5秒有效操作时间。在97公里时速下完成“识别—判断—转向—制动”的操作链,这要求人类在0.8秒内做出两次精准转向。更值得反思的是,涉事车辆此前17分钟持续发出“轻度分心报警”。这种温水煮青蛙式的安全暗示,让驾驶员在潜意识里形成“系统可靠”的依赖。
新能源汽车的竞争本应是安全底线之上的科技创新,但如今尴尬的是,“既要相信系统,又要随时接管”,成为当前智驾发展中的最大悖论。
自动驾驶虽然尚未到来,但是人们已经越来越多依赖趋近于自动驾驶的辅助驾驶功能,这些功能被车企以L2+级辅助驾驶的名义下放。在L2+级辅助驾驶仍有局限的情况下,人们却已经习惯于依赖系统,由此引发一系列事故。
“人们开始把驾驶座当沙发,这是比算法漏洞更危险的认知陷阱。”中国消费者协会投诉部主任王芳指出。
因此有必要重估当前智能驾驶系统的边界,并在这一过程中厘清驾驶员、车企和监管者的责任。对行业来说,每次对安全问题的避重就轻,可能都会透支整个行业的未来。而对驾驶员而言,必须充分认识到智能驾驶技术的局限性,不能将生命完全交给算法。



纯视觉路线的争议
小米SU7车祸引发的第一个争议便是纯视觉路线是否可靠。
事故车型为小米SU7标准版,该版本NOA采用纯视觉路线,没有安装激光雷达。而更高端的Pro版、Max版和Ultra版则采用“视觉+激光雷达”的路线。
特斯拉一直被视为“纯视觉”路线的代表,2024年以来,国内车企也开始更为积极地尝试纯视觉路线,如小鹏甚至被认为全面转向纯视觉路线。
智能驾驶可以被分为感知、决策和执行三部分。在感知环节,主流做法曾是使用激光雷达、摄像头等多种传感器,以减轻车辆感知环节压力。特斯拉则放弃激光雷达,只使用摄像头采集的视觉数据。这是一个马斯克用第一性原理思考的案例,既然人开车时只采集视觉信息,机器开车时也应如此。
对于纯视觉路线究竟是否存在短板的问题,清华大学苏州汽车研究院智能网联中心技术总监孙辉告诉《中国新闻周刊》,纯视觉路线的短板主要在于三个方面:深度感知局限,高动态场景(反光、逆光)适应性弱,以及夜晚、雨雾场景性能衰减明显。“在算力允许的情况下,从获取信息完备的角度看,‘视觉+激光雷达’一定优于纯视觉。两种方案的差距主要体现在对不规则、稀有障碍物的判断上,纯视觉主要依赖模型的泛化能力,因此存在一定的漏检风险,尤其是在光线不足或过曝时,更可能失去感知能力。”
不过,相比于纯视觉路线是否可靠的疑问,一个更重要的问题可能是国内车企的纯视觉路线是否可靠。有业内人士告诉《中国新闻周刊》:“不能简单对比两条路线的优劣。作为‘纯视觉’路线代表,特斯拉FSD能力就比较强。”
但是国内车企在硬件与模型训练层面相比特斯拉均有差距。
比如对于“纯视觉”路线的一个质疑在于其夜间表现。“目前多数特斯拉仍在使用3.0版本硬件,配备8个200万像素摄像头,144 TOPS算力,这一版本硬件的摄像头夜间成像可能存在问题。但是新款Model Y使用4.0版本硬件,配备8个500万像素索尼摄像头,720 TOPS算力。索尼摄像头在光照强度仅有1勒克斯左右,也就是没有月光的夜间也能清晰成像,而在光照强度为8万—10万勒克斯的夏天正午,也不会过度曝光,所以这款摄像头对照度的适应范围远超人眼。”有长期关注智能驾驶领域的学者告诉《中国新闻周刊》,“相比之下,国内车企可能配备数量更多的摄像头,基本包括前后两只800万像素摄像头,但是摄像头对照度的适应范围可能不及特斯拉使用的索尼摄像头,可能导致夜间成像质量存疑。”
而在前述业内人士看来,国内车企在车载摄像头、芯片等硬件方面的配置尚可,但是训练算力与数据的缺失才是关键。
在孙辉看来,纯视觉路线主要从硬件与软件两方面提升表现,软件方面的提升主要依赖数据,大模型训练需要海量数据,尤其是Corner case(边缘场景)数据,这些数据的数量和质量决定了智驾系统的表现。
前述学者进一步解释称,国内车企训练算力普遍不足,而且一些车企用户数据闭环刚刚建成,甚至还没有建成,而仅仅依靠数据采集能采集的数据量有限。特斯拉V12版本FSD使用1000万段,每段1分钟时长的用户数据。如果1分钟对应的行驶距离是1公里,这意味其使用1000万公里用户驾驶数据,如此数据量难以通过数据采集的方式完成,从采集到标注的成本为七八十亿元,因此没有车企能够依靠数据采集的方式积累足够的数据。
有国内第三方智驾方案供应商告诉记者,在数据方面,特斯拉相比国内厂商确实具备很大优势,因其具有先发优势。据他预估,如果一家车企累计销量超过百万辆,便会具备“相对可以”的模型训练数据基础。
“由于算力与数据的不足,国内车企‘纯视觉’路线相比特斯拉FSD普遍存在差距,而且‘激光雷达+视觉’路线的功能性、安全性都优于纯视觉路线。”前述业内人士直言,国内车企没有激光雷达的辅助驾驶系统“差很多”。
在他看来,国内车企从去年开始密集发布“纯视觉”路线,更多还是出于降本考虑。“目前激光雷达的价格还在3000元—7000元之间,从车企采购零部件成本的角度来看,每增加1000元都十分艰难。尽管有激光雷达厂商声称售价已在千元以下,但是前提是一次性大量采购。”他认为,今年被视为智驾平权元年,这意味着智能驾驶成为“标配”,因此车企首先在较低价位车型放弃激光雷达。
智驾局限何在?
哪怕是同一款车型,不同配置的辅助驾驶系统也不尽相同,但是车企在介绍一款车型的辅助驾驶能力时,往往仅介绍其高配版本拥有的能力,而一些低配版本甚至可能不搭载辅助驾驶系统。
车企的宣传话术确实容易让消费者丧失警惕。但是另一方面,哪怕是一款车具备辅助驾驶功能,人们也往往容易忽视其局限性。比如小米SU7三款车型中,相比于Pro版、Max版,虽然标准版不配备激光雷达,车载算力更低,但是同样具备高速NOA功能。
人们已经习惯于在高速场景使用辅助驾驶功能,但是近年数次高速车祸引发人们对于辅助驾驶的讨论。
“高速NOA与城市NOA实现的难度可谓天壤之别。但是从风险角度来讲,人类驾驶员在熟悉城市场景后,再到高速场景驾驶,但是辅助驾驶功能却优先在高速场景推出。企业潜意识认为高速NOA容易达成,不过是将车道保持、定速巡航等功能组合。”前述业内人士表示。
即使是在当前较为成熟的高速场景,辅助驾驶依然有明显短板。孙辉表示,在高速NOA中,比较常见的短板有施工、事故等突发场景应对不佳、异形车识别效果不理想、紧急避险策略较保守,也就是倾向于刹车,易导致被追尾事故。
其中,施工场景确实是高速NOA的重要局限,近年很多引发外界对于辅助驾驶讨论的事故都发生在高速公路维修路段。
“车企还没有认真对待道路维修工况,比如AEB对于锥桶、水马等无法正常响应,根源在于对于这样的场景训练不足。高速公路维修路段是一个典型的Corner case(边缘场景),车企没有针对这种场景采集到足够多的数据,甚至没有对这些数据进行处理。”前述学者认为。
他表示,首先,高速公路维修路段到来前,会在沿途LED显示屏上提示,但是恐怕没有辅助驾驶系统会识别提示文字。其次,在维修路段,会设置道路指引标识牌,系统能否识别这样的标识牌也存在疑问。再次,维修道路往往会安排渐进式限速,比如此次发生事故的维修路段,限速40公里/小时。但是这些限速标识牌往往并不规范,驾驶员看到限速从120公里/小时逐渐下降到80公里/小时、60公里/小时、40公里/小时的时候能准确理解,但是辅助驾驶系统可能难以连贯地理解这些渐近式限速标识牌。“目前智驾系统在使用Transformer模型时,尽管算法已经改进,但由于车载算力有限,一般也只会关联前后4帧,约40毫秒的信息,这意味系统的‘记忆’有限,而由于系统默认在高速公路行驶,并不会识别这些限速标识。因此与其盯住事故发生前的最后三秒,不如多去问问,为什么此前车辆并未减速。”
正是因为像高速公路施工这样的边缘场景仍然存在,真正的自动驾驶才难以到来。汽车自动驾驶技术被划分为L0至L5六个级别,L3级是分界线,L3级及以上为自动驾驶。尽管国内车企不断推出L2+、L2.9等概念,但是仍然称不上自动驾驶。
“不要说还剩下1%的边缘场景,哪怕只剩下0.01%的边缘场景,依然不能离开驾驶员。”前述业内人士感慨,没有人能回答还剩下多少待解决的边缘场景。
真正实现自动驾驶就需要解决边缘场景的问题,不过这并非易事。对于驾驶而言,人工智能与人类容易犯的错误不同。人类最容易犯的错误是疲劳驾驶、分心驾驶,系统既不会疲劳,也不会分心,而是取决于训练。但是由于车载算力的限制,大模型、推理模型目前还难以应用于车端,车端更多应用深度学习模型,其不具备大模型、推理模型的泛化、推理能力,因此更容易在边缘场景出现问题,也就是所谓的“黑天鹅问题”,如果在天鹅这一标签下录入1万张白天鹅照片,深度学习模型不会将一只黑天鹅照片识别为天鹅,从而出现误判。
特斯拉最初希望通过“大力出奇迹”的方式解决这一问题,特斯拉FSD V12版本已经覆盖30亿公里的行驶里程数据,V13版本的下一个目标是覆盖约100亿公里的行驶里程数据,但是这显然没有穷尽所有驾驶场景。
前述学者告诉记者,目前,像理想等车企也在尝试将视觉语言模型与现有的深度学习模型相结合,赋予系统一定推理能力,从而解决“黑天鹅问题”,但这仍取决于车端算力的突破。深度学习模型的参数级别约为10亿级,而所谓大模型的参数级别至少在百亿级。今年车载算力应该会突破1000 TOPS,接近1500 TOPS,也就是使用两颗英伟达Thor芯片,而明年可能会突破2000 TOPS,这意味着比较好的推理模型可以“上车”。“随着车载算力的提升,以及智能驾驶模型的进步,边缘场景的问题有可能被更好地解决。”